4 min to read
Resolving Duplicate Log Issues in Fluent Bit to OpenSearch Integration
How to prevent duplicate log storage using Generate_ID configuration in EKS environment
Overview
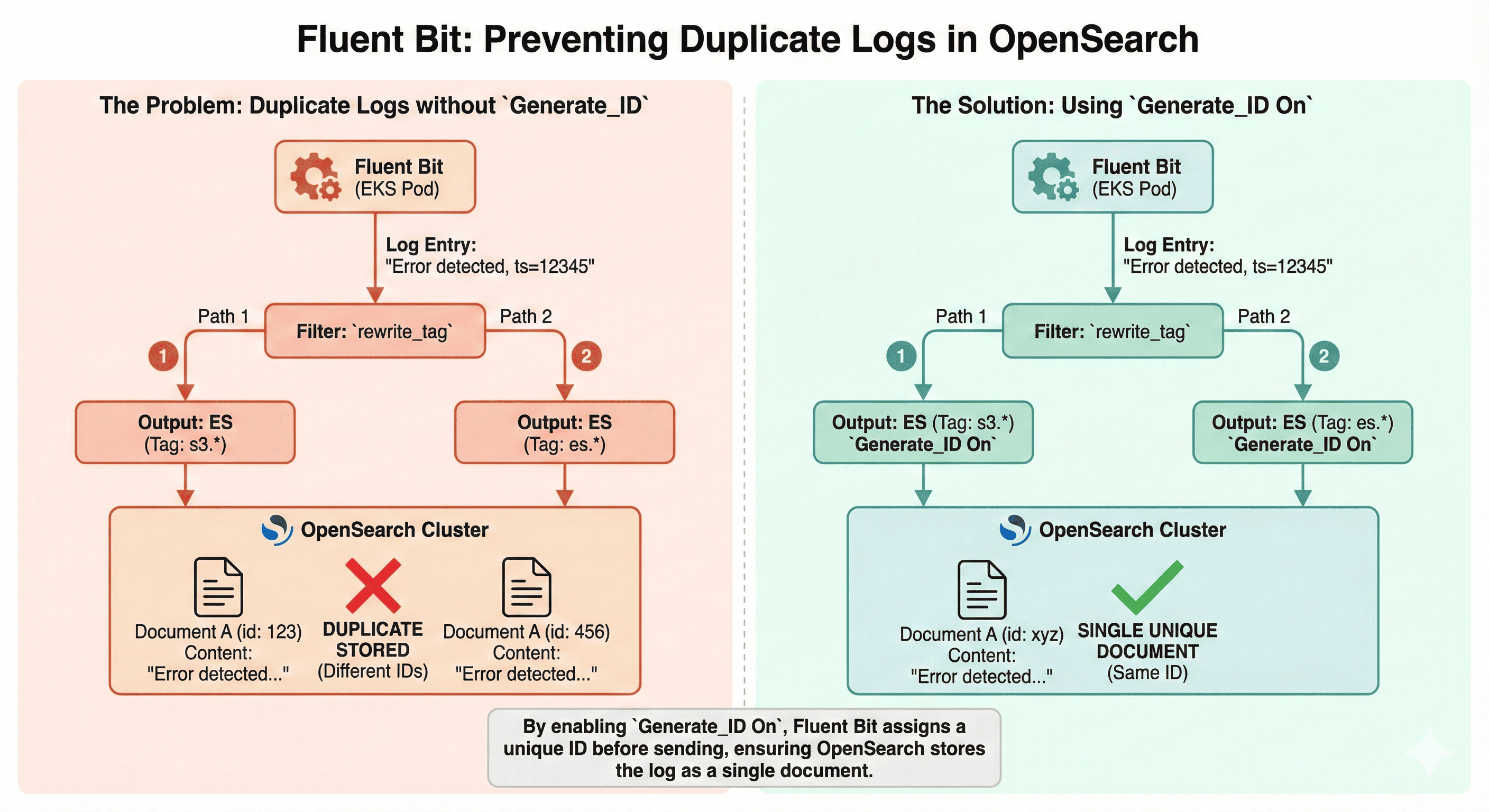
Have you ever experienced duplicate logs being stored in OpenSearch when forwarding logs through Fluent Bit in an EKS environment?
We faced a similar issue. Despite having identical log content and timestamps, logs were being stored twice in OpenSearch, causing metrics and search results to be artificially inflated.
After investigation, we discovered that each log had different _id values, causing OpenSearch to recognize them as separate documents.
This article shares a real case study of resolving this issue solely through Fluent Bit configuration. Specifically, we’ll explain the phenomenon where logs with identical content but different _id values get stored as duplicates, and how we resolved this using the Generate_ID setting.
Problem Situation
While using aws-for-fluent-bit in an AWS EKS environment to forward Fluent Bit logs to OpenSearch, we encountered an issue where identical logs were being stored multiple times.
In the OpenSearch dashboard, logs with identical messages and timestamps were being stored as duplicates, causing the following problems:
Impact of Duplicate Logs:
- Search result counts became inflated beyond actual values
- Log-based alerts were triggered multiple times
- Visualization metrics became distorted
Root Cause Analysis
When Fluent Bit sends logs to OpenSearch without specifying an _id, OpenSearch automatically generates a unique _id for each log. In this case, even if the content is identical, duplicate storage occurs due to different _id values.
Problem Analysis
In our environment, the rewrite_tag filter caused identical logs to propagate through multiple paths within Fluent Bit, with each path generating different _id values, resulting in storage as separate documents in OpenSearch.
Conditions Where This Problem Occurs More Frequently:
Logstash_Format Onoption is configuredGenerate_IDoption is disabled- Identical logs are sent through multiple OUTPUT paths
As a result, OpenSearch stores logs with identical content but different _id values as duplicate documents.
Solution
This issue can be resolved by adding the following option to the Fluent Bit es Output configuration.
Configuration Update
[OUTPUT]
Name es
Match es.*
...
Generate_ID On
How Generate_ID Works:
The Generate_ID On option forces Fluent Bit to generate a unique _id internally when sending logs to OpenSearch. This ensures that even if identical logs are forwarded through multiple paths, OpenSearch recognizes them as the same document and stores only one copy.
Why This Setting is Essential
This configuration is particularly essential when using rewrite_tag filters to forward logs through multiple Match paths. When identical logs are split and sent to s3.*, es.* paths, if _id is not forcibly generated, logs will have different _id values despite identical content. This results in the same log being stored 2 or more times in OpenSearch.
Verification and Follow-up Actions
After applying the configuration, verify the following items to ensure the solution is working correctly.
Verification Steps
Post-Implementation Verification:
- Confirm in the OpenSearch dashboard that logs with identical messages and timestamps are stored only once
- Compare the
_idpatterns of logs with Generate_ID applied to verify that uniqueness is ensured - Continuously monitor through Health Check paths to ensure logs are being sent normally without errors or retries in Fluent Bit logs
- If necessary, simplify rewrite_tag filter logic to reduce the possibility of duplicate tagging
Key Points
-
Problem Cause
- Different _id values for identical log content
- OpenSearch treating them as separate documents
- Multiple paths through rewrite_tag filters -
Solution
- Enable Generate_ID in Fluent Bit OUTPUT configuration
- Ensures consistent _id generation for identical logs
- Prevents duplicate storage in OpenSearch -
Prevention
- Proper _id management in multi-path logging
- Regular monitoring of log storage patterns
- Optimization of filtering and tagging strategies
Conclusion
This issue appeared to be a simple case of duplicate log storage, but the root cause lay in the _id generation mechanism between Fluent Bit and OpenSearch. Fortunately, we were able to completely resolve the problem with a single Generate_ID option provided by Fluent Bit.
When integrating Fluent Bit with OpenSearch in EKS environments, it's important to apply configurations that prevent _id conflicts or duplicate generation in advance, especially when considering multi-path log routing scenarios.
Moving forward, it’s necessary to continuously inspect log storage structures and refine filtering and tagging strategies. This experience reinforces how a small configuration change can make a significant difference in data quality and operational efficiency.

Comments