4 min to read
Resolving DB Connection Error (ECONNRESET) Issues
How to fix database connection issues in Kubernetes IPVS environment using conntrack and TCP keepalive settings
Overview
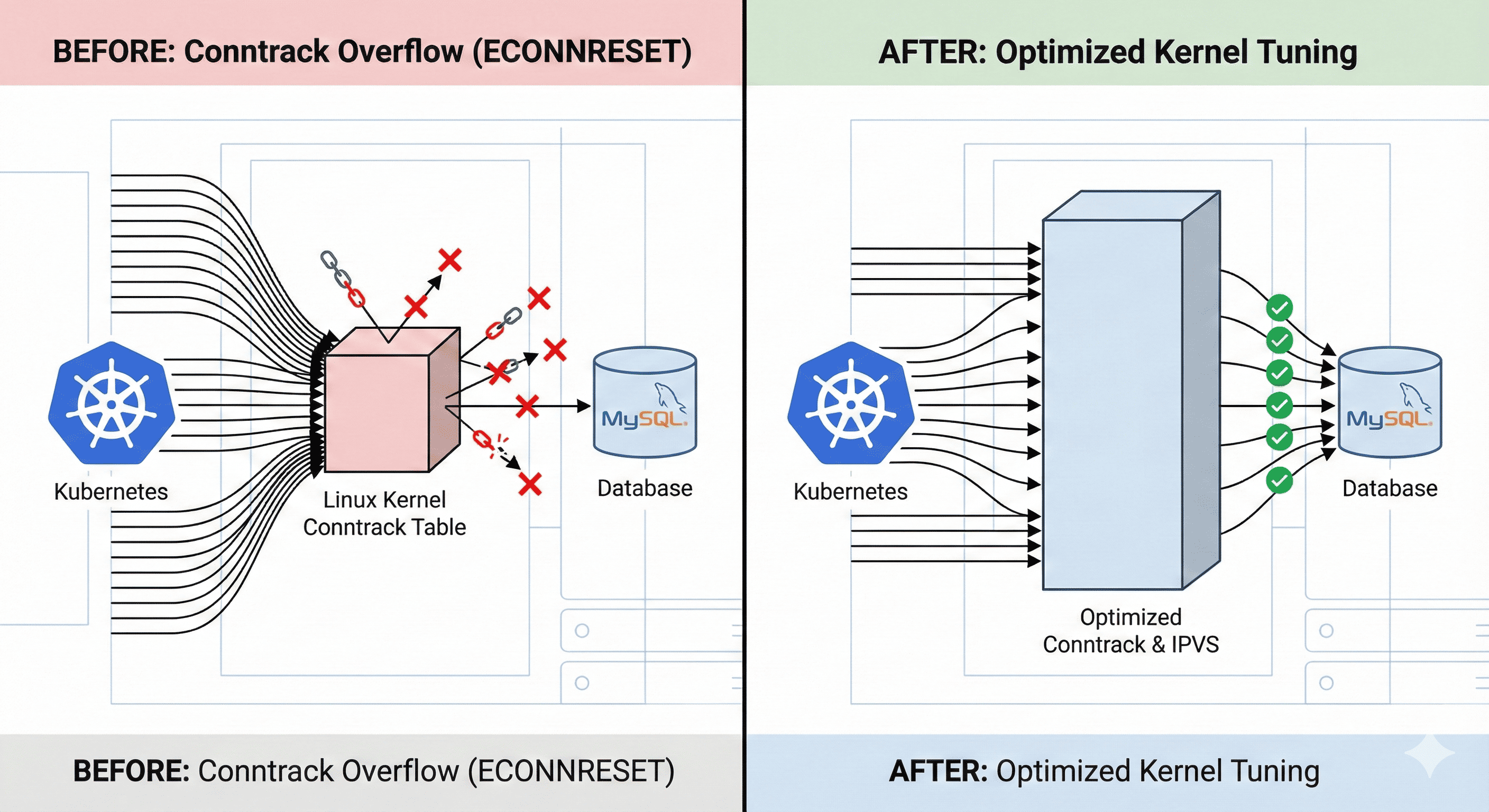
In Kubernetes environments, “ECONNRESET” errors can occur when database connections to MySQL or RDS become unstable.
Particularly when using IPVS environments, abnormal database connection terminations frequently occur when large numbers of concurrent connections or network sessions accumulate.
This article shares a case study of resolving DB connection disconnection issues by adjusting conntrack, IPVS, and TCP keepalive related settings.
Problem Situation
We encountered frequent connection issues when services attempted to query MySQL databases, manifesting as specific error patterns and infrastructure-level problems.
Symptoms Observed
Error Patterns:
read ECONNRESETerrors occurred frequently when querying MySQL- Logs from OpenSearch or Loki showed socket-level connection drops
- Kubernetes kube-proxy was configured in IPVS mode
- Conntrack configuration was set to default maximum connection values
Root Cause Analysis
The investigation revealed three main factors contributing to the connection issues, all related to kernel-level network management in IPVS environments.
1. Conntrack Capacity Exceeded
- IPVS uses kernel’s conntrack functionality to manage session state
- When conntrack table becomes full, new connections cannot be tracked
- This causes DB connection requests to be dropped or terminated
sudo dmesg | grep -i conntrack
# [ 123.456789] nf_conntrack: table full, dropping packet.
2. IPVS Timeout and Conntrack Timeout Mismatch
When conntrack terminates connections faster than IPVS maintains them, connection issues occur.
3. Inadequate TCP Keepalive Settings
TCP connections terminate too quickly in situations requiring long-term inter-node connection maintenance.
Solution
The resolution involved systematic adjustment of multiple kernel-level network parameters to ensure stable database connections in the IPVS environment.
1. Increase Conntrack Settings
sudo sysctl -w net.netfilter.nf_conntrack_max=131072
sudo sysctl -w net.netfilter.nf_conntrack_buckets=32768
Parameter Explanation:
nf_conntrack_max: Number of connections that can be tracked simultaneouslynf_conntrack_buckets: Hash table bucket count (recommended 1/4 of max)
2. Increase IPVS Timeout
sudo ipvsadm --set 7200 120 300
sudo ipvsadm -Ln --timeout
# Timeout (tcp tcpfin udp): 7200 120 300
Timeout Configuration:
- 7200s: TCP connection maintenance
- 120s: FIN-WAIT timeout
- 300s: UDP timeout
3. Adjust TCP Keepalive
sudo sysctl -w net.ipv4.tcp_keepalive_time=7200
sudo sysctl -w net.ipv4.tcp_keepalive_intvl=75
sudo sysctl -w net.ipv4.tcp_keepalive_probes=5
Maintains long-term idle connections to prevent premature termination.
4. Fine-tune Conntrack Timeout
sudo sysctl -w net.netfilter.nf_conntrack_tcp_timeout_established=7200
sudo sysctl -w net.netfilter.nf_conntrack_tcp_timeout_time_wait=120
sudo sysctl -w net.netfilter.nf_conntrack_udp_timeout=300
sudo sysctl -w net.netfilter.nf_conntrack_udp_timeout_stream=300
Important Note:
Aligning timeouts between IPVS and conntrack is crucial for maintaining stable connections.
5. Persistent Configuration (/etc/sysctl.d/99-custom.conf)
net.netfilter.nf_conntrack_max=131072
net.netfilter.nf_conntrack_buckets=32768
net.ipv4.tcp_keepalive_time=7200
net.ipv4.tcp_keepalive_intvl=75
net.ipv4.tcp_keepalive_probes=5
net.netfilter.nf_conntrack_tcp_timeout_established=7200
net.netfilter.nf_conntrack_tcp_timeout_time_wait=120
net.netfilter.nf_conntrack_udp_timeout=300
net.netfilter.nf_conntrack_udp_timeout_stream=300
Verification and Monitoring
After implementing the configuration changes, it’s important to verify the effectiveness and establish ongoing monitoring for connection stability.
Verification Steps
- Monitor application logs for reduction in ECONNRESET errors
- Check conntrack table utilization with
cat /proc/sys/net/netfilter/nf_conntrack_count - Verify IPVS timeout settings with
ipvsadm -Ln --timeout - Monitor database connection pool metrics
Recommended Monitoring
- Set up Prometheus + Grafana for conntrack metrics monitoring
- Implement automated alerting for conntrack table usage
- Monitor database connection error rates
- Track TCP connection state distributions
Key Points
-
Problem Identification
- ECONNRESET errors due to conntrack table overflow
- IPVS and conntrack timeout misalignment
- Inadequate TCP keepalive configuration -
Solution Approach
- Increase conntrack capacity and buckets
- Align IPVS and conntrack timeouts
- Configure appropriate TCP keepalive settings -
Best Practices
- Implement persistent configuration files
- Establish comprehensive monitoring
- Regular capacity planning for high-concurrency scenarios
Conclusion
When database connections frequently drop or ECONNRESET errors occur, it’s easy to misinterpret these as simple application bugs. However, by examining IPVS, conntrack, and TCP kernel settings, the root cause of such issues can often be resolved at the infrastructure network layer.
As demonstrated in this case, adjusting conntrack_max, ipvsadm --set, and keepalive settings can maintain database connection stability even in scenarios with thousands to tens of thousands of concurrent connections.
For high-availability environments, it’s recommended to also implement Prometheus + Grafana-based conntrack metrics monitoring and automated alerting systems to proactively manage connection stability.

Comments