13 min to read
Advanced Ceph Erasure Code Configuration and Performance Optimization
Complete guide to implementing Erasure Code in Ceph clusters for storage efficiency and data protection
Overview
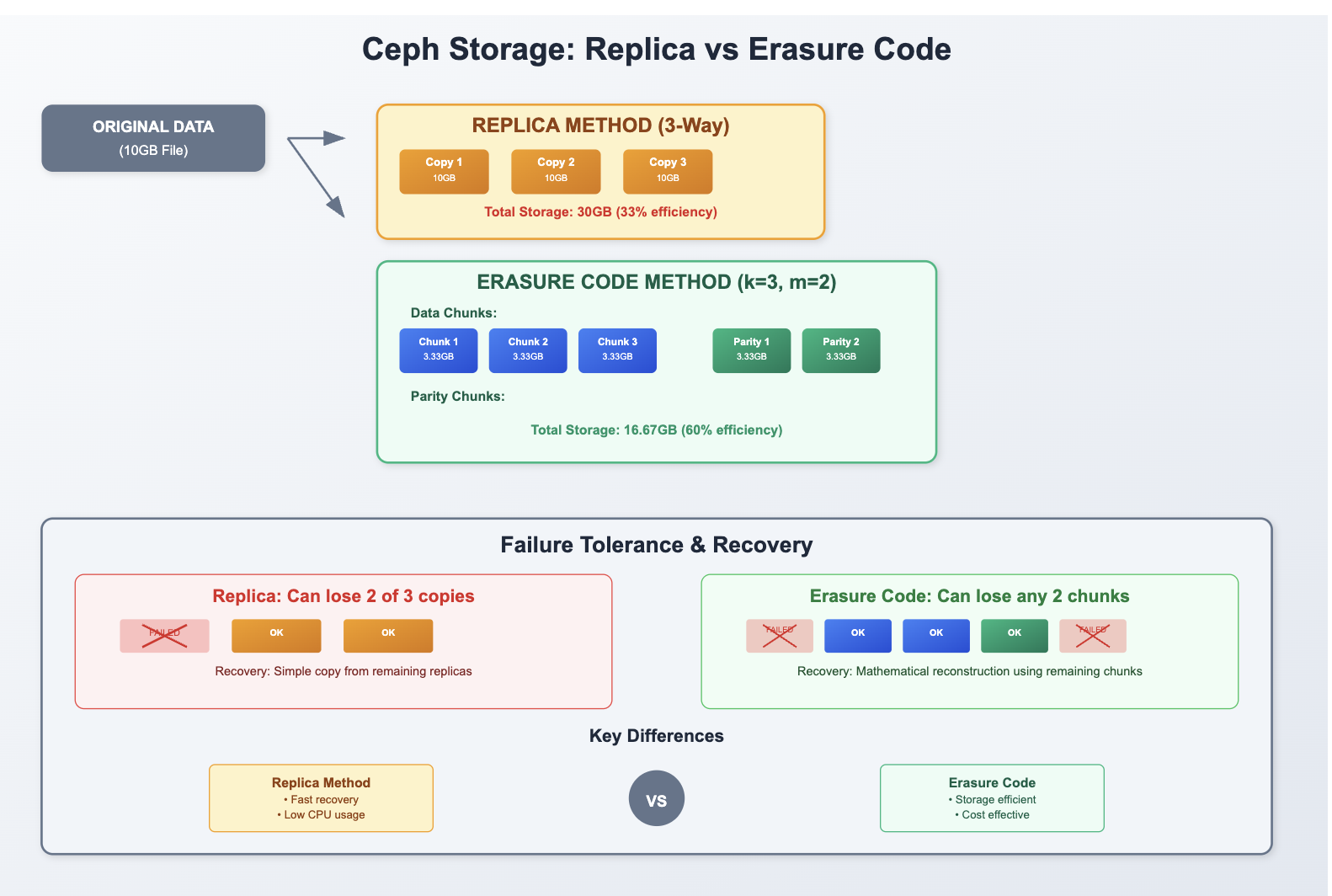
In large-scale storage systems, achieving both reliability and efficiency simultaneously presents significant challenges. Ceph addresses this through two distinct data protection methods: Replica and Erasure Code.
This article focuses primarily on Erasure Code configuration and practical implementation, highlighting its superior storage efficiency. We’ll explore the fundamental differences between Replica and Erasure Code approaches, provide step-by-step configuration guides, and address common troubleshooting scenarios.
Erasure Code offers substantial storage savings while maintaining high availability, making it ideal for environments where storage cost optimization is critical without compromising data durability.
What is Erasure Code?
Erasure Code is a data protection method that divides data into multiple chunks (k) and adds recovery chunks (m), storing the complete dataset across N = k + m blocks.
This approach enables data recovery even when some blocks are lost, providing resilience through mathematical redundancy rather than simple replication.
Key Characteristics:
- Data Segmentation: Original data split into k data chunks
- Parity Generation: m parity chunks calculated from data chunks
- Fault Tolerance: Can survive up to m chunk failures
- Storage Efficiency: Significantly better than traditional replication
Example Configuration:
# k=3, m=2 configuration
# - 3 data chunks + 2 parity chunks = 5 total chunks
# - Can survive up to 2 chunk failures
# - Storage efficiency: 3/5 = 60% (vs 33% for 3-way replication)
Replica vs Erasure Code Comparison
| Aspect | Replica Method | Erasure Code Method |
|---|---|---|
| Data Protection | Identical data copies | Data segmentation + parity |
| Storage Efficiency | Very Low (33% for 3-replica) | High (60% for k=3,m=2) |
| Recovery Speed | Fast (simple copy) | Slower (parity calculation) |
| CPU/Compute Load | Low | High (parity operations) |
| Network Overhead | High (full data copies) | Lower (distributed chunks) |
| Suitable Environment | Fast recovery critical | Storage space optimization |
| Minimum OSDs | Equal to replica count | k + m |
| Failure Tolerance | n-1 failures | m failures |
Infrastructure Requirements
Minimum Cluster Configuration
| Component | Requirement | Recommendation |
|---|---|---|
| OSDs | k + m (minimum) | k + m + 2 (for maintenance) |
| Memory | 4GB per OSD | 8GB per OSD |
| Network | 1Gbps | 10Gbps |
| CPU | 1 core per OSD | 2 cores per OSD |
| Failure Domains | k + m distinct domains | Well-distributed topology |
Example Cluster Topology
# 3-node cluster example for k=3, m=2
Node 1: 2 OSDs (rack-1)
Node 2: 2 OSDs (rack-2)
Node 3: 1 OSD (rack-3)
Total: 5 OSDs across 3 failure domains
Erasure Code Profile Configuration
Step 1: Verify Cluster Status
# Check Ceph version
ceph --version
# Verify cluster health
ceph -s
# Check OSD status
ceph osd tree
# Verify available failure domains
ceph osd crush tree
Step 2: Create Erasure Code Profile
Profile Parameters Explanation:
# Core Parameters
k=3 # Number of data chunks
m=2 # Number of parity chunks
plugin=jerasure # Erasure coding algorithm
# Advanced Parameters
technique=reed_sol_van # Specific technique within plugin
crush-failure-domain=host # Failure domain for chunk placement
crush-device-class=ssd # Restrict to specific device class
Step 3: Verify Profile Creation
# List all erasure code profiles
ceph osd erasure-code-profile ls
# Display profile details
ceph osd erasure-code-profile get ec-profile-advanced
# Expected output:
# crush-device-class=ssd
# crush-failure-domain=host
# k=4
# m=2
# plugin=jerasure
# technique=reed_sol_van
Pool Creation and Management
Step 1: Calculate Placement Groups (PGs)
# Formula: (OSDs * 100) / (k + m) / pool_count
# Example: (12 OSDs * 100) / 6 / 2 pools = 100 PGs
# Round to nearest power of 2: 128 PGs
# For production environments, use Ceph PG calculator:
# https://ceph.io/pgcalc/
Step 2: Create Erasure Code Pool
# Create pool with calculated PGs
ceph osd pool create ec-pool-storage 128 erasure ec-profile-advanced
# Verify pool creation
ceph osd pool ls detail | grep ec-pool-storage
# Check pool status
ceph osd pool get ec-pool-storage all
Step 3: Configure Pool for Applications
# Enable for RGW (Object Storage)
ceph osd pool application enable ec-pool-storage rgw
# Enable for RBD (Block Storage) - requires metadata pool
ceph osd pool create ec-pool-metadata 32 replicated
ceph osd pool application enable ec-pool-metadata rbd
ceph osd pool application enable ec-pool-storage rbd
# Enable for CephFS (File Storage)
ceph osd pool application enable ec-pool-storage cephfs
Performance Optimization
Step 1: CRUSH Map Optimization
# Extract current CRUSH map
ceph osd getcrushmap -o crushmap.bin
crushtool -d crushmap.bin -o crushmap.txt
# Edit crushmap.txt to optimize placement rules
# Add custom rules for erasure code pools
# Compile and inject updated CRUSH map
crushtool -c crushmap.txt -o crushmap-new.bin
ceph osd setcrushmap -i crushmap-new.bin
Custom CRUSH Rule Example:
# Custom rule in crushmap.txt
rule ec_ssd_rule {
id 1
type erasure
min_size 3
max_size 6
step take default class ssd
step chooseleaf firstn 0 type host
step emit
}
Step 2: Configure Pool Parameters
# Set optimal parameters for erasure code pool
ceph osd pool set ec-pool-storage pg_num 128
ceph osd pool set ec-pool-storage pgp_num 128
# Optimize for read performance
ceph osd pool set ec-pool-storage fast_read true
# Configure compression (optional)
ceph osd pool set ec-pool-storage compression_algorithm zstd
ceph osd pool set ec-pool-storage compression_mode force
Step 3: Monitor Performance Metrics
# Check pool statistics
ceph df detail
# Monitor I/O performance
ceph osd perf
# Check placement group distribution
ceph pg dump | grep ec-pool-storage
# Monitor erasure code operations
ceph daemon osd.0 perf dump | grep erasure
RBD Integration with Erasure Code
Step 1: Create Metadata and Data Pools
# Create replicated metadata pool
ceph osd pool create rbd-metadata 32 replicated
# Create erasure code data pool
ceph osd pool create rbd-ec-data 128 erasure ec-profile-advanced
# Enable RBD application
ceph osd pool application enable rbd-metadata rbd
ceph osd pool application enable rbd-ec-data rbd
Step 2: Configure RBD with Erasure Code Backend
# Create RBD image with erasure code data pool
rbd create --size 10G --data-pool rbd-ec-data rbd-metadata/test-image
# Verify image configuration
rbd info rbd-metadata/test-image
# Expected output:
# rbd image 'test-image':
# size 10 GiB in 2560 objects
# order 22 (4 MiB objects)
# data_pool: rbd-ec-data
Step 3: Kubernetes StorageClass Configuration
# rbd-ec-storageclass.yaml
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rbd-erasure-code
annotations:
storageclass.beta.kubernetes.io/is-default-class: "false"
provisioner: rbd.csi.ceph.com
parameters:
clusterID: "b9127830-b0cc-4e34-aa47-9d1a2e9949a8"
pool: "rbd-metadata"
dataPool: "rbd-ec-data"
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: csi-rbd-secret
csi.storage.k8s.io/provisioner-secret-namespace: kube-system
csi.storage.k8s.io/controller-expand-secret-name: csi-rbd-secret
csi.storage.k8s.io/controller-expand-secret-namespace: kube-system
csi.storage.k8s.io/node-stage-secret-name: csi-rbd-secret
csi.storage.k8s.io/node-stage-secret-namespace: kube-system
csi.storage.k8s.io/fstype: ext4
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
- discard
Troubleshooting Common Issues
Issue 1: Degraded Data Redundancy
Symptoms:
HEALTH_WARN
Degraded data redundancy: 122 pgs undersized
Root Causes:
- Insufficient OSDs for k+m configuration
- OSDs not distributed across required failure domains
- OSD failures exceeding tolerance threshold
Resolution Steps:
# Check OSD distribution
ceph osd tree
# Verify failure domain configuration
ceph osd crush tree
# Add more OSDs if needed
ceph-volume lvm create --data /dev/sdX
# Check PG mapping
ceph pg ls-by-pool ec-pool-storage | head -10
# Force PG repair if necessary
ceph pg repair <pg_id>
Issue 2: Pool Application Not Enabled
Symptoms:
HEALTH_WARN
1 pool(s) do not have an application enabled
Resolution:
# Enable appropriate application
ceph osd pool application enable ec-pool-storage rgw
# Verify application status
ceph osd pool application get ec-pool-storage
Issue 3: Slow Recovery Performance
Symptoms:
- Extended recovery times
- High CPU utilization during recovery
- Network bandwidth saturation
Optimization Steps:
# Adjust recovery parameters
ceph config set osd osd_recovery_max_active 3
ceph config set osd osd_max_backfills 1
ceph config set osd osd_recovery_sleep 0.1
# Monitor recovery progress
ceph -s | grep recovery
# Check individual OSD performance
ceph daemon osd.0 perf dump | grep recovery
Issue 4: CRUSH Rule Conflicts
Symptoms:
HEALTH_ERR
Pool 'ec-pool-storage' has no available OSDs for pg X.Y
Resolution:
# Check current CRUSH rules
ceph osd crush rule ls
ceph osd crush rule dump
# Verify pool's CRUSH rule
ceph osd pool get ec-pool-storage crush_rule
# Create appropriate CRUSH rule
ceph osd crush rule create-erasure ec-rule ec-profile-advanced
# Apply rule to pool
ceph osd pool set ec-pool-storage crush_rule ec-rule
Monitoring and Maintenance
Step 1: Setup Monitoring Scripts
Step 2: Automated Health Checks
# Create cron job for regular monitoring
cat > /etc/cron.d/ceph-monitoring << 'EOF'
# Monitor Ceph erasure code pools every 15 minutes
*/15 * * * * root /usr/local/bin/ceph-ec-monitor.sh >> /var/log/ceph-monitoring.log 2>&1
EOF
Step 3: Performance Baselines
# Establish performance baselines
echo "=== Storage Efficiency Comparison ===" > /var/log/ceph-baseline.log
# Calculate storage efficiency
TOTAL_RAW=$(ceph df | grep TOTAL | awk '{print $2}')
TOTAL_USED=$(ceph df | grep TOTAL | awk '{print $4}')
EFFICIENCY=$(echo "scale=2; $TOTAL_USED / $TOTAL_RAW * 100" | bc)
echo "Raw Storage: $TOTAL_RAW" >> /var/log/ceph-baseline.log
echo "Used Storage: $TOTAL_USED" >> /var/log/ceph-baseline.log
echo "Efficiency: $EFFICIENCY%" >> /var/log/ceph-baseline.log
# I/O performance baseline
rados bench -p ec-pool-storage 30 write > /var/log/ceph-write-baseline.log
rados bench -p ec-pool-storage 30 seq > /var/log/ceph-read-baseline.log
Best Practices and Recommendations
Production Deployment Guidelines
- Capacity Planning
- Plan for k+m+2 OSDs minimum for maintenance windows
- Consider network bandwidth for erasure code operations
- Account for increased CPU requirements
- Failure Domain Design
- Distribute OSDs across physical racks or availability zones
- Ensure each failure domain can handle chunk placement
- Plan for correlated failures (power, network)
- Performance Optimization
- Use fast SSDs for metadata pools
- Optimize CRUSH rules for data locality
- Monitor and tune recovery parameters
When to Choose Erasure Code
| Scenario | Recommendation | Rationale |
|---|---|---|
| Cold Storage | Erasure Code | Storage efficiency priority |
| Backup Systems | Erasure Code | Cost optimization critical |
| Archive Data | Erasure Code | Infrequent access patterns |
| Hot Database | Replica | Performance critical |
| Real-time Analytics | Replica | Low latency required |
| Mixed Workloads | Hybrid Approach | Balance efficiency and performance |
Configuration Templates
Conclusion
Erasure Code represents a significant advancement in storage efficiency for Ceph clusters, offering substantial cost savings while maintaining high durability.
The configuration complexity is offset by dramatic improvements in storage utilization, making it essential for large-scale deployments.
Key Achievements:
- Storage Efficiency: Up to 60-80% storage utilization vs 33% with 3-way replication
- Scalability: Better resource utilization for large datasets
- Flexibility: Multiple profiles for different use cases
- Integration: Seamless Kubernetes and application integration
Operational Benefits:
- Cost Reduction: Significant hardware cost savings
- Data Durability: Configurable failure tolerance
- Performance Optimization: Tunable parameters for different workloads
- Automated Management: Integration with existing Ceph tools
Future Considerations:
- Evaluate emerging erasure code algorithms
- Implement automated tier migration between replica and erasure code pools
- Develop application-specific optimization profiles
- Consider hybrid storage architectures
Mastering Erasure Code configuration enables organizations to build cost-effective, highly durable storage systems that scale efficiently with growing data requirements.
“Erasure Code transforms storage economics by delivering enterprise-grade durability at a fraction of traditional replication costs.”


Comments