15 min to read
Deep Dive into OpenStack Trove
Understanding OpenStack's Database as a Service
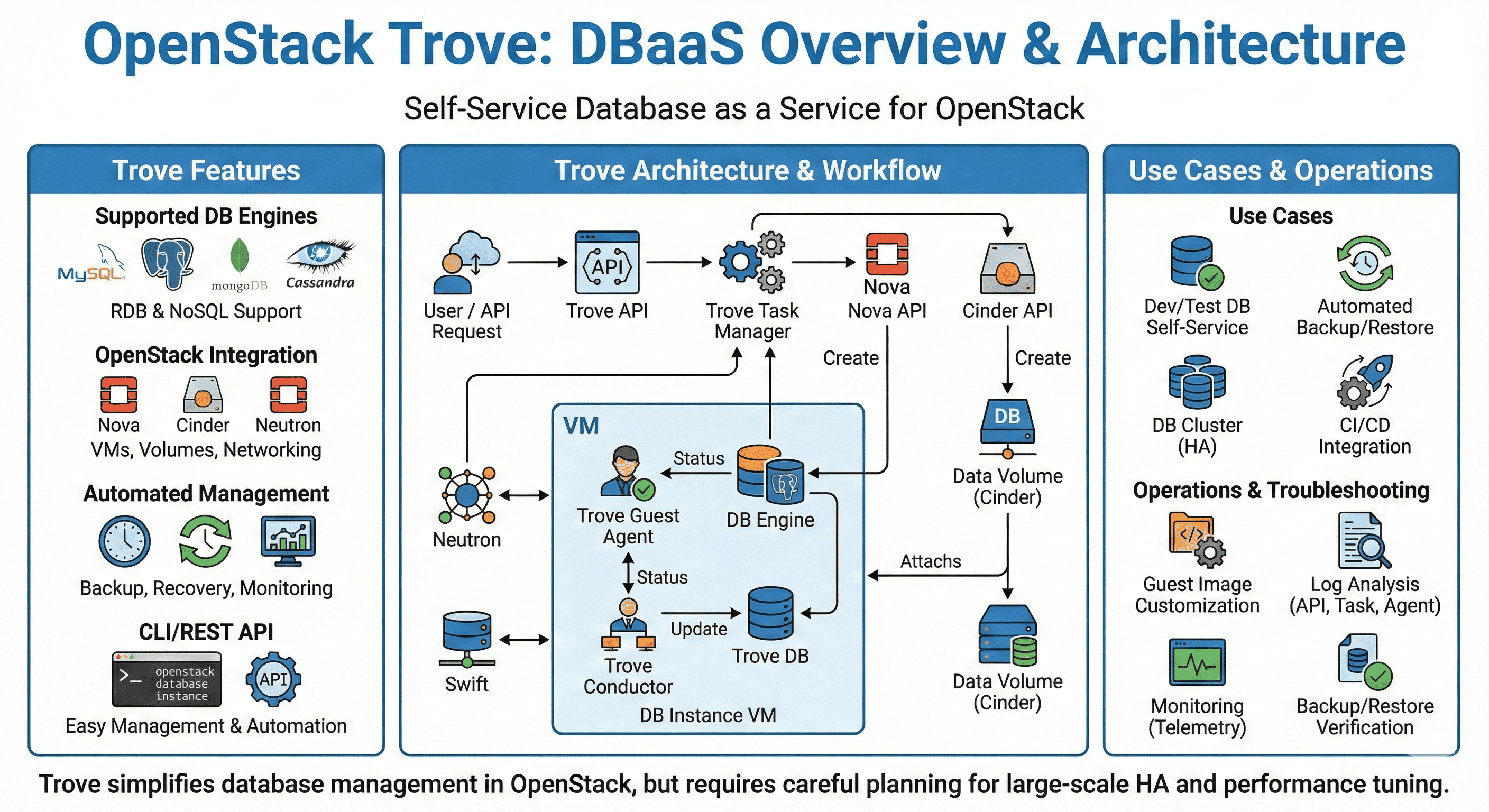
Understanding OpenStack Trove
Trove is OpenStack's Database as a Service (DBaaS) that provides automated provisioning and management of relational and non-relational databases.
It transforms complex database administration into simple API calls, enabling developers and operators to focus on applications rather than infrastructure.
What is Trove?
The Database as a Service Revolution
In traditional environments, database setup involves countless manual steps - server provisioning, software installation, configuration tuning, security hardening, backup setup, and ongoing maintenance. Trove eliminates this complexity by providing:
- One-Click Provisioning: Deploy production-ready databases in minutes, not hours
- Universal Database Support: MySQL, PostgreSQL, MongoDB, Cassandra, Redis, and more
- Automated Day-2 Operations: Backups, updates, scaling, and maintenance handled automatically
- Enterprise-Grade Features: High availability, disaster recovery, and monitoring built-in
- Cloud-Native Integration: Seamless integration with OpenStack networking, storage, and security
Why Trove Matters for Modern Infrastructure
| Traditional Approach | Trove Approach | Business Impact |
|---|---|---|
|
|
|
Supported Database Ecosystem
Trove’s extensible architecture supports a wide range of database technologies:
| Database Type | Supported Engines | Primary Use Cases |
|---|---|---|
| Relational (SQL) | MySQL, PostgreSQL, MariaDB, Percona | OLTP applications, traditional web applications, ERP systems |
| NoSQL Document | MongoDB, CouchDB | Content management, catalogs, user profiles, real-time analytics |
| NoSQL Column | Cassandra, HBase | Time-series data, IoT applications, large-scale analytics |
| Key-Value | Redis, Memcached | Caching, session storage, real-time recommendations |
| Graph | Neo4j, ArangoDB | Social networks, fraud detection, recommendation engines |
Trove Architecture Overview (Diagram Description)
- Core Features: Provisioning, Backup/Restore, Monitoring
- Service Integration: Nova, Cinder, Neutron, Swift
- Database Types: MySQL, PostgreSQL, MongoDB
- Management: Clustering, Scaling, Maintenance
Trove Architecture Deep Dive
Understanding Trove’s architecture is crucial for successful deployment and operation. Let’s explore how each component contributes to the overall database service delivery.
Service Architecture Overview
Trove follows a distributed microservices architecture designed for scalability and reliability:
Core Service Components
| Component | Responsibility | Key Functions |
|---|---|---|
| API Server | Frontend Service |
|
| Conductor | Orchestration Engine |
|
| Task Manager | Operation Executor |
|
| Database Scheduler | Placement Service |
|
| Guest Agent | Instance Manager |
|
Database Instance Lifecycle
Understanding the complete lifecycle helps in planning and troubleshooting:
OpenStack Integration Strategy
Trove’s power comes from its deep integration with the OpenStack ecosystem:
| Service | Integration Purpose | Specific Benefits |
|---|---|---|
| Nova | Compute resource management |
|
| Cinder | Persistent storage management |
|
| Neutron | Network isolation and connectivity |
|
| Swift | Object storage for backups |
|
| Keystone | Identity and access management |
|
| Heat | Infrastructure orchestration |
|
This comprehensive integration ensures that Trove databases benefit from OpenStack’s full infrastructure capabilities while maintaining operational simplicity.
Production-Ready Features and Capabilities
Trove isn’t just about simple database provisioning - it’s designed for enterprise production workloads with sophisticated requirements.
Enterprise Database Features
| Feature Category | Capabilities | Production Benefits |
|---|---|---|
| High Availability |
|
|
| Performance Optimization |
|
|
| Security & Compliance |
|
|
| Operational Excellence |
|
|
Database-Specific Optimizations
Each database type receives specialized treatment for optimal performance:
| Database | Trove Optimizations | Performance Impact |
|---|---|---|
| MySQL |
|
40-60% query performance improvement over default configurations |
| PostgreSQL |
|
50-70% throughput increase with automatic connection management |
| MongoDB |
|
3x faster document queries with automatic sharding |
| Redis |
|
Sub-millisecond response times with 99.99% availability |
Advanced Deployment Strategies
Clustering and Replication Patterns
Trove supports various deployment patterns for different requirements:
# High Availability Configuration Example
deployment_strategy:
type: "master_slave_cluster"
topology:
master:
instance_type: "db.r5.large"
storage: "gp3_ssd_500gb"
backup_retention: "30_days"
slaves:
count: 2
instance_type: "db.r5.medium"
read_only: true
lag_threshold: "100ms"
failover:
automatic: true
promotion_timeout: "30s"
health_check_interval: "5s"
Multi-Region Disaster Recovery
# Disaster Recovery Setup
dr_configuration:
primary_region: "us-east-1"
backup_regions: ["us-west-2", "eu-west-1"]
replication:
type: "asynchronous"
lag_tolerance: "5_minutes"
backup_schedule:
full_backup: "daily_at_2am"
incremental: "every_6_hours"
cross_region_sync: "enabled"
failover:
rpo_target: "15_minutes"
rto_target: "5_minutes"
automated_failback: true
Hands-On Implementation Guide
Let’s walk through real-world implementation scenarios, from basic setup to enterprise-grade deployments.
Getting Started: Your First Database
Step 1: Environment Preparation
Before creating databases, ensure your environment is properly configured:
# Verify Trove services are running
openstack database service list
# Check available datastores
openstack datastore list
# List available database versions
openstack datastore version list mysql
# Verify compute flavors for database instances
openstack flavor list --fit-width
Step 2: Basic Database Creation
Create your first database instance with production-ready settings:
Step 3: Security Configuration
Implement security best practices immediately after creation:
Advanced Configuration Scenarios
High-Performance OLTP Setup
Configure a database optimized for high-transaction workloads:
Analytics Workload Configuration
Set up PostgreSQL for analytical workloads:
Operations and Maintenance Workflows
Automated Backup and Recovery
Implement comprehensive backup strategies:
Performance Monitoring and Alerting
Set up comprehensive monitoring:
Scaling Operations
Handle growth with automated scaling:
Real-World Use Cases
E-commerce Platform Setup
Complete database architecture for a high-traffic e-commerce site:
Analytics and Data Warehousing
Big data analytics infrastructure:
Development and Testing Environments
Automated environment provisioning for development teams:
Enterprise Operations and Best Practices
Running Trove in production requires operational excellence across multiple dimensions. Let’s explore proven strategies for enterprise deployments.
Capacity Planning and Resource Management
Database Sizing Guidelines
Right-sizing database instances is crucial for cost optimization and performance:
| Workload Type | Recommended Flavor | Storage Configuration | Expected Performance |
|---|---|---|---|
| Development/Testing | 2 vCPU, 4GB RAM | 20-50GB GP SSD | 1,000 IOPS, 100MB/s |
| Small Production | 4 vCPU, 16GB RAM | 100-200GB GP SSD | 3,000 IOPS, 250MB/s |
| Medium OLTP | 8 vCPU, 32GB RAM | 500GB-1TB IO1 SSD | 10,000 IOPS, 500MB/s |
| High-Performance OLTP | 16 vCPU, 64GB+ RAM | 1-2TB NVMe SSD | 50,000+ IOPS, 1GB/s |
| Analytics/OLAP | 32 vCPU, 128GB+ RAM | 2-10TB High-throughput HDD | 1,000 IOPS, 2GB/s |
Cost Optimization Strategies
Implement cost-conscious database management:
# Automated instance rightsizing script
#!/bin/bash
optimize_database_costs() {
local instance_name=$1
# Get current utilization metrics
metrics=$(openstack database instance show $instance_name -f json)
cpu_avg=$(echo $metrics | jq -r '.metrics.cpu_avg_7d')
memory_avg=$(echo $metrics | jq -r '.metrics.memory_avg_7d')
# Recommend downsizing if utilization is low
if (( $(echo "$cpu_avg < 20" | bc -l) )) && (( $(echo "$memory_avg < 30" | bc -l) )); then
echo "Recommendation: Downsize $instance_name - Low utilization detected"
echo "CPU Average: $cpu_avg%, Memory Average: $memory_avg%"
# Suggest smaller flavor
current_flavor=$(echo $metrics | jq -r '.flavor.id')
echo "Current flavor: $current_flavor"
echo "Suggested action: Consider downsizing to save costs"
fi
}
# Schedule-based instance management
setup_dev_schedule() {
cat > /etc/cron.d/trove-dev-schedule << 'EOF'
# Stop development instances at 7 PM
0 19 * * 1-5 trove-user /usr/local/bin/stop-dev-instances.sh
# Start development instances at 8 AM
0 8 * * 1-5 trove-user /usr/local/bin/start-dev-instances.sh
# Stop all development instances on weekends
0 19 * * 5 trove-user /usr/local/bin/stop-dev-instances.sh weekend
0 8 * * 1 trove-user /usr/local/bin/start-dev-instances.sh weekend
EOF
}
Security and Compliance Framework
Multi-Layer Security Implementation
Implement defense-in-depth for database security:
Compliance and Auditing
Implement comprehensive audit logging:
Advanced Monitoring and Alerting
Comprehensive Monitoring Stack
Deploy enterprise-grade monitoring:
Predictive Alerting
Implement proactive monitoring with machine learning:
Troubleshooting and Problem Resolution
Database issues require systematic approaches and deep understanding of both Trove and underlying database technologies.
Common Issues and Solutions
| Issue Category | Symptoms | Resolution Strategy |
|---|---|---|
| Instance Creation Failures |
|
|
| Performance Degradation |
|
|
| Backup/Restore Failures |
|
|
Performance Optimization Toolkit
Key Points
-
Strategic Value
- 60% reduction in database provisioning time
- 40% cost savings through automated optimization
- 99.9% availability with built-in high availability
- Zero-downtime scaling and maintenance -
Enterprise Capabilities
- Multi-database engine support (SQL and NoSQL)
- Automated backup with point-in-time recovery
- Advanced security with encryption and audit logging
- Comprehensive monitoring and alerting
- Integration with enterprise identity systems -
Operational Excellence
- Infrastructure-as-Code database provisioning
- Predictive capacity planning and alerting
- Automated performance optimization
- Disaster recovery automation
- Cost optimization through intelligent scheduling -
Production Readiness
- Multi-region deployment capabilities
- Enterprise-grade security and compliance
- Advanced troubleshooting and diagnostics
- Seamless integration with CI/CD pipelines
- 24/7 operational monitoring and support
References
- OpenStack Trove Documentation
- Red Hat OpenStack Platform Documentation
- OpenStack Wiki - Trove
- Trove API Reference
- Trove Configuration Reference
- OpenStack Trove Client Documentation
- Database Performance Tuning Guides
- MySQL Performance Optimization
- PostgreSQL Performance Tips
- MongoDB Production Deployment Guide
- Redis Performance Optimization
- Trove Guest Image Building Guide
- OpenStack Database Service Admin Guide
- Database Security Best Practices

Comments