7 min to read
Deep Dive into OpenStack Heat
Understanding OpenStack's Orchestration Service
Understanding OpenStack Heat
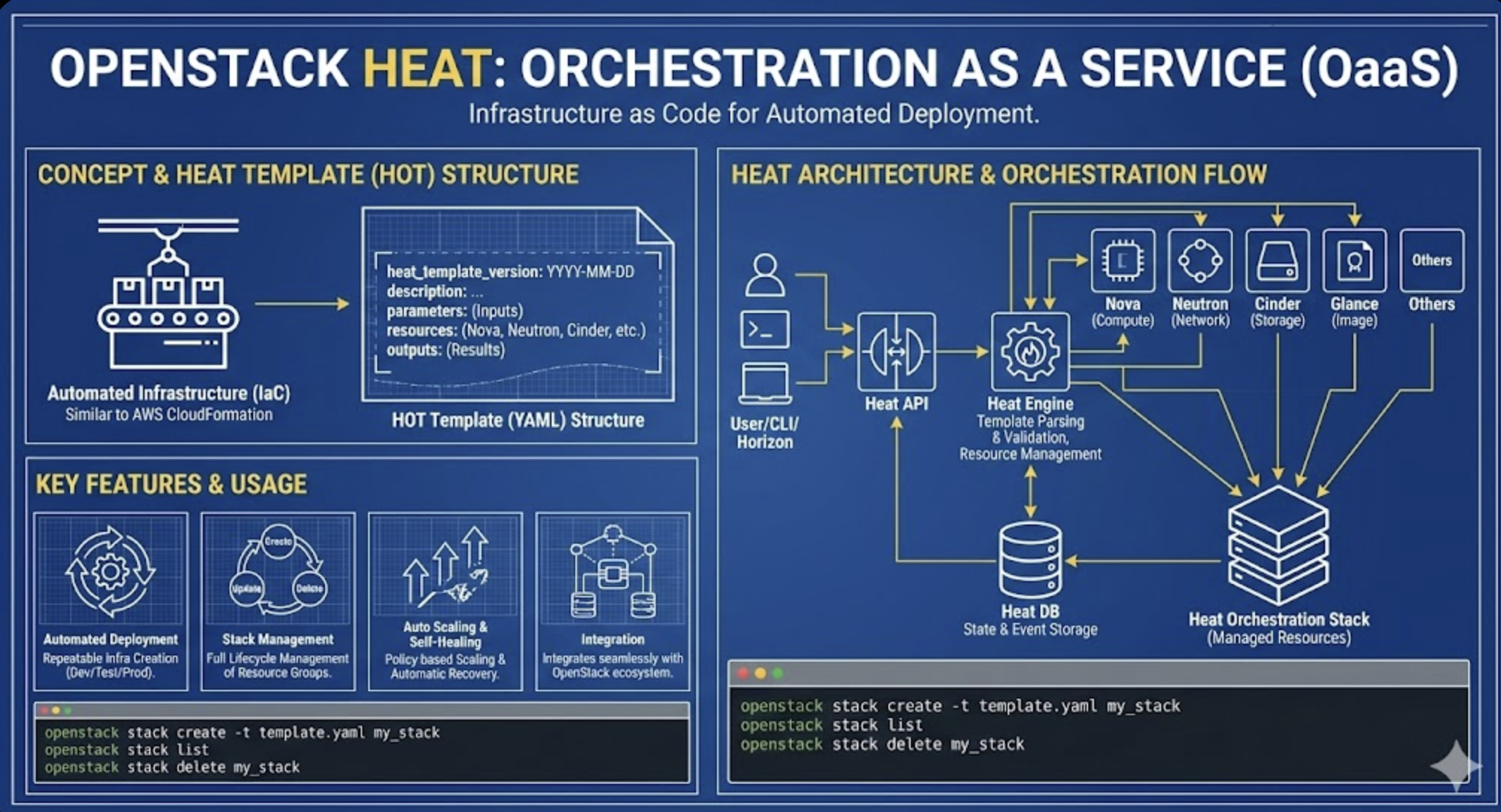
Heat is OpenStack’s orchestration service that enables infrastructure automation through templates.
It allows users to define cloud infrastructure as code and automate the deployment and management of cloud resources.
What is Heat?
The Orchestration Service
Heat serves as OpenStack’s orchestration engine, providing essential functionality:
- Infrastructure as Code: Define infrastructure using YAML templates
- Automated Deployment: Deploy and manage cloud resources automatically
- Service Integration: Coordinate multiple OpenStack services
- Template Management: Version control and template reuse
Similar to AWS CloudFormation, Heat enables consistent and repeatable infrastructure deployment.
Heat Architecture Overview (Diagram Description)
- OpenStack Heat
- Core Features: Infrastructure as Code, Automated Deployment, Stack Management
- Service Integration: Nova, Neutron, Cinder
- Template Management: HOT Templates, Version Control, Template Reuse
- Resource Control: Resource Creation, Update, Deletion
Heat Architecture and Components
Heat’s architecture consists of several key components that work together to provide orchestration capabilities.
Each component plays a specific role in the orchestration process.
Core Components
| Component | Role | Description |
|---|---|---|
| Heat API | API Service |
|
| Heat Engine | Orchestration Engine |
|
| Heat CLI | Command Line Interface |
|
| Heat Template | Infrastructure Definition |
|
Template Structure
Heat Orchestration Template (HOT)
Heat templates use YAML format with key components:
heat_template_version: Template version specificationdescription: Template descriptionparameters: Input parameters definitionresources: Resource definitionsoutputs: Output valuesheat_template_version: 2018-08-31 description: Simple Heat Example parameters: image_id: type: string description: Image ID for the instance resources: my_instance: type: OS::Nova::Server properties: name: ExampleVM image: { get_param: image_id } flavor: m1.small
Key Features and Capabilities
Heat provides comprehensive orchestration capabilities that enable automated infrastructure management and deployment.
These features make it a powerful tool for cloud automation.
Core Features
| Feature | Description | Benefits |
|---|---|---|
| Automated Deployment | Deploy infrastructure using templates |
|
| Stack Management | Group and manage related resources |
|
| Auto Scaling | Automatic resource scaling |
|
Service Integration
Heat integrates with various OpenStack services:
- Nova: Compute instance management
- Neutron: Network resource configuration
- Cinder: Block storage management
- Glance: Image management
- Keystone: Authentication and authorization
This integration enables comprehensive infrastructure automation.
Usage and Best Practices
Effective use of Heat requires understanding its capabilities and implementing appropriate management practices.
Here are key considerations and best practices for utilizing Heat effectively.
Implementation Guidelines
| Guideline | Description | Benefits |
|---|---|---|
| Template Design | Create modular, reusable templates |
|
| Parameter Usage | Use parameters for flexibility |
|
| Resource Management | Organize resources logically |
|
Common Operations
Basic Heat Operations
- Stack Creation:
openstack stack create -t template.yaml stack_name - Stack Listing:
openstack stack list - Stack Deletion:
openstack stack delete stack_name
These operations form the basis of Heat management.
Advanced Configuration (Production Hardening)
Template Patterns & Structure
| Pattern | Description | Benefits |
|---|---|---|
| Nested Stacks | Compose large systems from child templates via OS::Heat::Stack |
Reuse modules, faster iteration, clearer ownership |
| Environments | Use environment.yaml to override parameters and resource mappings |
Promotes dev/stage/prod parity with minimal diffs |
| Resource Registry | Map abstract types to concrete providers (e.g., custom resources) | Vendor abstraction, easier backend swaps |
| Outputs & Exports | Expose values for cross-stack consumption | Composable architectures and decoupling |
Security & Secrets Management
- Barbican Integration: Store sensitive parameters (passwords/keys) in Barbican and reference from Heat
- No Secrets in Git: Keep secrets out of templates; pass via environment files or parameter stores
- Keystone RBAC: Limit who can create/update/delete stacks; audit with Keystone logs
- TLS Everywhere: Ensure API and metadata endpoints are protected with TLS
Performance & Convergence
- Convergence Engine: Use Heat convergence for parallel resource operations and drift correction
- Batching & Dependencies: Model minimal dependencies to maximize parallelism; avoid serial bottlenecks
- Idempotency: Design resources so updates are safe and no-op when unchanged
- Long-Running Ops: Increase timeouts for large stacks; provide progress via stack events
High Availability (HA) Deployment
| Component | Recommendation | Notes |
|---|---|---|
| Heat API | 2+ instances behind L7 load balancer | Stateless; share DB and message bus |
| Heat Engine | Multiple workers consuming from queue | Horizontal scale for large stacks |
| DB/Queue | HA Galera / RabbitMQ cluster | Proper quorum and monitoring |
Observability & Operations
- Metrics: Track stack operation duration, success/failure counts, engine queue depth
- Logging: Structured logs with request/stack IDs for end-to-end tracing
- Health Checks: Liveness/readiness for API and engine; synthetic tests for critical stacks
- Runbooks: Document rollback, update-failure recovery, and orphan resource cleanup
CI/CD for Templates
- Linting: Validate HOT with linters; enforce schema correctness in pipelines
- Unit Tests: Mock resources and test Jinja rendering/parameter expansion
- Dry-Run: Use stack previews/validations before apply; promote via environments
Troubleshooting Playbook (Quick Checks)
- Stack CREATE_FAILED: Inspect stack events; verify parameter types and resource names
- Update Stalls: Check engine workers and message bus; confirm convergence enabled
- Dependency Errors: Minimize circular refs; split into nested stacks
- Drift Issues: Run convergence to reconcile; avoid out-of-band changes
- Quota Exceeded: Validate Nova/Cinder/Neutron quotas before large deployments
Key Points
-
Core Functionality
- Infrastructure as Code
- Automated deployment
- Stack management
- Service integration -
Key Features
- Template-based deployment
- Auto scaling support
- Resource orchestration
- Service coordination -
Best Practices
- Modular templates
- Parameter usage
- Resource organization
- Version control


Comments