31 min to read
Understanding the Linux Kernel - Architecture, Functionality, and Internals
A comprehensive guide to the Linux Kernel architecture and functionality
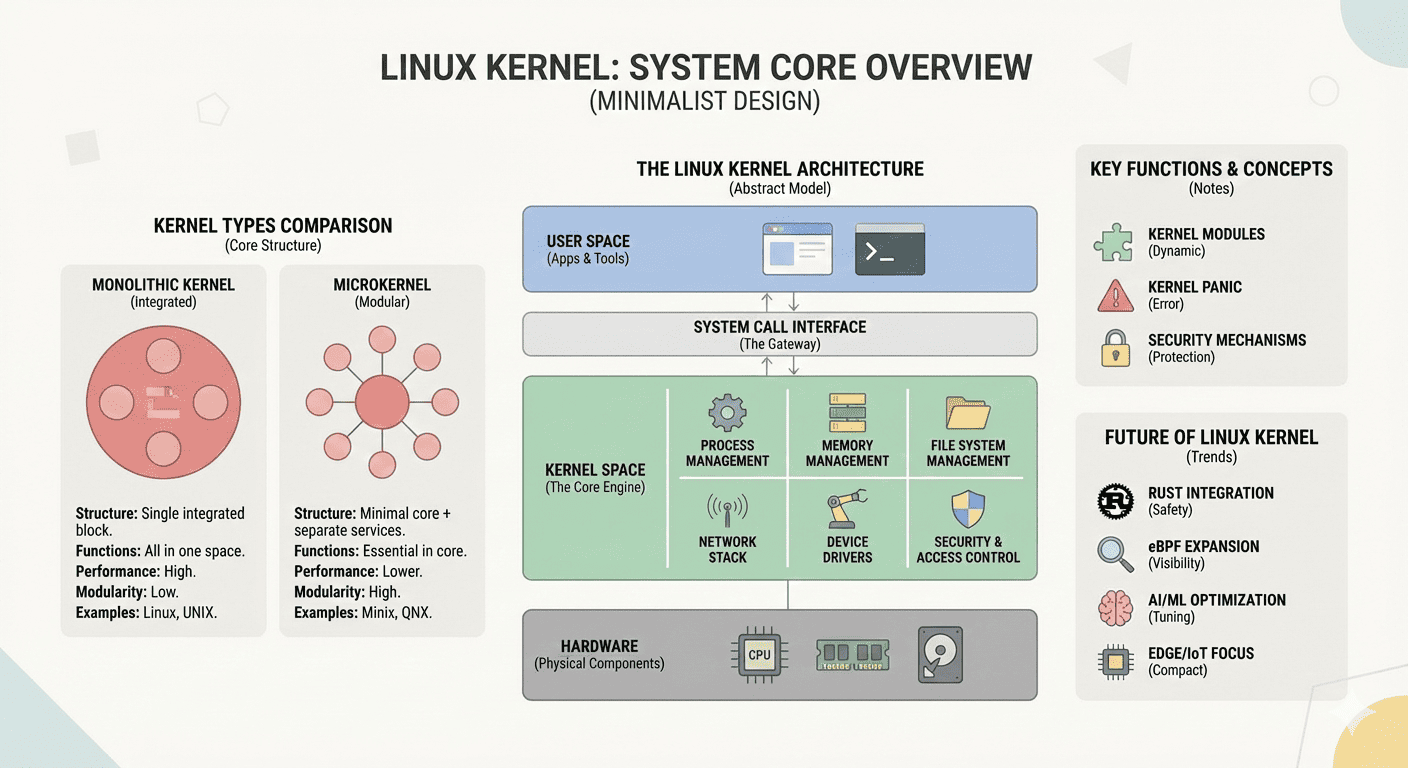
What is the Linux Kernel?
The Linux Kernel is the fundamental core of the Linux operating system - a sophisticated software layer that serves as the critical bridge between hardware components and user applications.
It manages system resources, provides essential services, and enables applications to function while abstracting the complexities of hardware interaction.
Historical Context
The Linux kernel was first created by Linus Torvalds in 1991 while he was a computer science student at the University of Helsinki. What began as a personal project to create a free alternative to the MINIX operating system has evolved into one of the most significant software projects in computing history.
Key milestones in kernel development:
- 1991: Version 0.01 - Initial release (approximately 10,000 lines of code)
- 1994: Version 1.0 - First stable release
- 1996: Version 2.0 - Added support for multiple architectures
- 2011: Version 3.0 - Primarily a numbering change
- 2015: Version 4.0 - Introduced live patching infrastructure
- 2019: Version 5.0 - Improved support for AMD FreeSync, Raspberry Pi
- 2023: Version 6.0 - Enhanced security, performance improvements
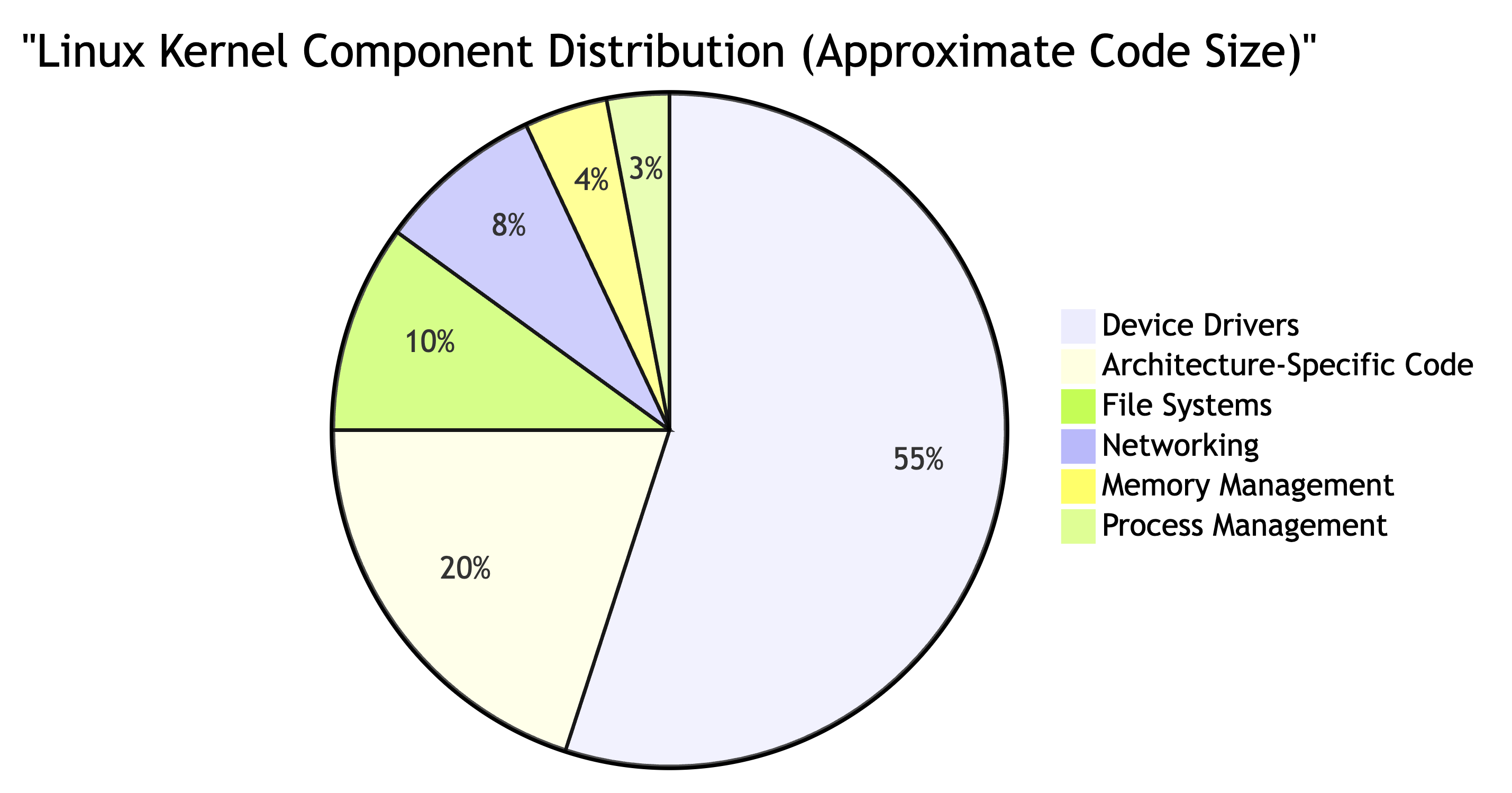
Today's Linux kernel exceeds 30 million lines of code with contributions from thousands of developers worldwide, making it one of the largest collaborative software projects ever created.
Kernel Architecture Overview
The Linux kernel utilizes a monolithic design with modular capabilities, combining the performance advantages of monolithic kernels with the flexibility of modular systems.
Monolithic vs. Microkernel Design
| Characteristic | Monolithic Kernel (Linux) | Microkernel |
|---|---|---|
| Architecture | Single large binary with all core services in kernel space | Minimal kernel with services in user space |
| Performance | Higher performance due to direct function calls within the kernel | Lower performance due to IPC (Inter-Process Communication) overhead |
| Memory Footprint | Larger memory footprint in kernel space | Smaller kernel but with overall similar total memory usage |
| Modularity | Loadable kernel modules provide some modularity | Inherently modular with isolated services |
| Reliability | Single failure can affect the entire kernel | Service failures can be isolated without affecting the kernel |
| Examples | Linux, FreeBSD, Solaris | MINIX, QNX, GNU Hurd |
Linux has successfully mitigated many of the traditional disadvantages of monolithic kernels through:
- Loadable Kernel Modules: Components can be loaded/unloaded at runtime
- Preemption Capabilities: Allows better responsiveness
- Error Containment: Mechanisms to isolate and recover from certain failures
- Unified Development Model: Consistent approach across all subsystems
Core Components and Subsystems
The Linux kernel can be divided into several major subsystems, each responsible for specific aspects of system functionality:
Process Management
Process management handles the creation, scheduling, and termination of processes, enabling multitasking in the Linux system.
Key Features:
- Process Scheduler: Determines which process runs when
- Process Control Block: Data structure containing all information about a process
- Context Switching: Mechanism to switch CPU execution from one process to another
- Thread Support: Native thread implementation via the
clone()system call
Process States:
Example: Process Creation
#include <unistd.h>
#include <stdio.h>
int main() {
pid_t child_pid;
// Create a new process
child_pid = fork();
if (child_pid == -1) {
// Error handling
perror("fork failed");
return 1;
} else if (child_pid == 0) {
// Child process code
printf("Child process: PID = %d\n", getpid());
} else {
// Parent process code
printf("Parent process: Child's PID = %d\n", child_pid);
}
return 0;
}
In this example, the fork() system call creates a new process by duplicating the calling process. The kernel handles the complex tasks of:
- Creating a new process control block
- Allocating process resources
- Copying parent’s memory space (with copy-on-write optimization)
- Scheduling the new process for execution
Memory Management
Memory management controls how processes access memory, implementing virtual memory and managing physical RAM allocation.
Memory Hierarchy
Key Components:
- Page Tables: Map virtual addresses to physical addresses
- Demand Paging: Loads pages into memory only when needed
- Memory Allocators:
- Buddy Allocator: For physical page allocation
- Slab Allocator: For kernel objects of fixed sizes
- Virtual Memory Areas (VMAs): Track process memory regions
- Out-of-Memory (OOM) Killer: Terminates processes when memory is critically low
Example: Memory Information
# Display comprehensive memory usage information
$ free -h
total used free shared buff/cache available
Mem: 15Gi 4.5Gi 6.2Gi 625Mi 4.9Gi 10Gi
Swap: 8.0Gi 0B 8.0Gi
# Examine kernel memory parameters
$ sysctl vm.swappiness
vm.swappiness = 60
# Analyze a process's memory maps
$ cat /proc/1234/maps
00400000-00452000 r-xp 00000000 08:02 173521 /usr/bin/example
00651000-00652000 r--p 00051000 08:02 173521 /usr/bin/example
...
# Monitor page faults and memory operations
$ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 6382888 95056 4915476 0 0 12 17 0 0 5 1 93 1 0
File System Layer
The Linux file system layer provides a unified interface for accessing various file systems while maintaining a consistent API for applications.
Architecture:
Key Concepts:
- Virtual File System (VFS): Abstract layer that provides a common interface
- Inodes: Data structures containing file metadata
- Dentries: Directory entry cache for pathname lookup optimization
- Mount Points: Connection points for file systems into the unified hierarchy
- Page Cache: Improves performance by caching file data in memory
Linux File System Operations
// Simplified example of reading from a file using system calls
#include <fcntl.h>
#include <unistd.h>
#include <stdio.h>
int main() {
int fd;
char buffer[128];
ssize_t bytes_read;
// Open file - kernel traverses the VFS
fd = open("/etc/hostname", O_RDONLY);
if (fd == -1) {
perror("Failed to open file");
return 1;
}
// Read file - kernel accesses the specific file system implementation
bytes_read = read(fd, buffer, sizeof(buffer) - 1);
if (bytes_read > 0) {
buffer[bytes_read] = '\0';
printf("Hostname: %s", buffer);
}
// Close file - kernel cleans up file descriptors
close(fd);
return 0;
}
This example demonstrates how user applications interact with the kernel’s file system layer through system calls, which are then routed through the VFS to the specific file system implementation (e.g., ext4, XFS) handling the requested file.
Device Drivers
Device drivers are the interface between the Linux kernel and hardware devices, enabling the kernel to communicate with a wide range of hardware.
Driver Architecture:
Driver Types:
- Character Device Drivers:
- For devices that are accessed as a stream of bytes (e.g., serial ports, keyboards)
- Accessed through special files in
/dev - Examples:
/dev/tty(terminals),/dev/random(random number generator)
- Block Device Drivers:
- For devices that handle data in fixed-size blocks (e.g., hard drives, SSDs)
- Support random access to data blocks
- Examples:
/dev/sda(SATA disk),/dev/nvme0n1(NVMe SSD)
- Network Device Drivers:
- For network interfaces (e.g., Ethernet cards, Wi-Fi adapters)
- Interface with the kernel’s networking stack
- Configured through interfaces like
eth0,wlan0
Working with Kernel Modules:
Device drivers in Linux are typically implemented as loadable kernel modules, allowing dynamic loading and unloading without rebooting.
# List all loaded kernel modules
$ lsmod
Module Size Used by
bluetooth 610304 0
rfkill 28672 4 bluetooth
snd_hda_codec_hdmi 61440 1
snd_hda_codec 135168 2 snd_hda_codec_hdmi
...
# Get information about a specific module
$ modinfo bluetooth
filename: /lib/modules/5.15.0-75-generic/kernel/net/bluetooth/bluetooth.ko
license: GPL
version: 2.22
description: Bluetooth Core ver 2.22
author: Marcel Holtmann <marcel@holtmann.org>
...
# Load a module
$ sudo modprobe i915 # Intel graphics driver
# Unload a module
$ sudo rmmod bluetooth
Device Driver Development Example:
This is a simplified example of a character device driver:
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/fs.h>
#include <linux/cdev.h>
#include <linux/device.h>
#include <linux/uaccess.h>
static int device_open(struct inode *, struct file *);
static int device_release(struct inode *, struct file *);
static ssize_t device_read(struct file *, char *, size_t, loff_t *);
static ssize_t device_write(struct file *, const char *, size_t, loff_t *);
static struct file_operations fops = {
.open = device_open,
.release = device_release,
.read = device_read,
.write = device_write
};
// Implementation of driver functions...
static int __init simple_init(void) {
// Register character device
printk(KERN_INFO "Simple driver: Initializing\n");
return 0;
}
static void __exit simple_exit(void) {
// Unregister character device
printk(KERN_INFO "Simple driver: Exiting\n");
}
module_init(simple_init);
module_exit(simple_exit);
MODULE_LICENSE("GPL");
MODULE_AUTHOR("Example Author");
MODULE_DESCRIPTION("A simple character device driver");
Networking Stack
The Linux networking stack is a sophisticated subsystem that handles network communication across various protocols and interfaces.
Networking Architecture:
Key Components:
- Socket Interface: API for applications to access network services
- Protocol Implementations: TCP, UDP, IP, ICMP, etc.
- Network Device Interface: Infrastructure for network device drivers
- Netfilter: Framework for packet filtering, network address translation (NAT)
- Routing Subsystem: Determines how packets are forwarded
- Network Namespaces: Virtualization for network resources
Socket Programming Example:
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main() {
int socket_fd;
struct sockaddr_in server_addr;
char buffer[1024] = "Hello from client";
// Create socket
socket_fd = socket(AF_INET, SOCK_STREAM, 0);
if (socket_fd < 0) {
perror("Socket creation failed");
return 1;
}
// Initialize server address structure
memset(&server_addr, 0, sizeof(server_addr));
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons(8080);
inet_pton(AF_INET, "127.0.0.1", &server_addr.sin_addr);
// Connect to server
if (connect(socket_fd, (struct sockaddr*)&server_addr, sizeof(server_addr)) < 0) {
perror("Connection failed");
return 1;
}
// Send message to server
send(socket_fd, buffer, strlen(buffer), 0);
printf("Message sent\n");
close(socket_fd);
return 0;
}
When this program runs, the socket system call initiates a complex chain of events in the kernel:
- A socket structure is allocated and initialized
- Protocol-specific operations are set up (TCP in this case)
- A file descriptor is returned to the application
- Subsequent operations (connect, send) invoke specific protocol handlers
Interprocess Communication (IPC)
Linux provides various mechanisms for processes to communicate with each other.
IPC Mechanisms:
| IPC Mechanism | Characteristics | Use Cases |
|---|---|---|
| Pipes | Unidirectional, related processes, FIFO queue | Shell pipelines, parent-child communication |
| Named Pipes (FIFOs) | Like pipes but accessible via filesystem path | Communication between unrelated processes |
| Message Queues | Structured messages with types, persistent | Client-server applications, event handling |
| Shared Memory | Fast, requires synchronization | High-performance data sharing, databases |
| Semaphores | Counting mechanism for synchronization | Controlling access to shared resources |
| Sockets | Network-transparent, flexible | Network communication, local process communication |
| Signals | Asynchronous notifications | Process termination, error handling |
Example: Pipe Communication
#include <stdio.h>
#include <unistd.h>
#include <string.h>
int main() {
int pipe_fd[2];
pid_t child_pid;
char message[] = "Message from parent";
char buffer[100];
// Create pipe
if (pipe(pipe_fd) == -1) {
perror("Pipe creation failed");
return 1;
}
// Create child process
child_pid = fork();
if (child_pid == -1) {
perror("Fork failed");
return 1;
}
if (child_pid == 0) {
// Child process
close(pipe_fd[1]); // Close write end
// Read from pipe
read(pipe_fd[0], buffer, sizeof(buffer));
printf("Child received: %s\n", buffer);
close(pipe_fd[0]);
} else {
// Parent process
close(pipe_fd[0]); // Close read end
// Write to pipe
write(pipe_fd[1], message, strlen(message) + 1);
printf("Parent sent message\n");
close(pipe_fd[1]);
}
return 0;
}
Kernel Space vs User Space
In Linux, memory and execution modes are divided into two distinct domains: kernel space and user space. This separation is fundamental to system security and stability.
Memory and Protection Rings
Key Differences
| Characteristic | Kernel Space | User Space |
|---|---|---|
| Access Level | Unrestricted access to hardware and memory | Limited access through system calls |
| Memory Addressing | Can access all physical and virtual memory | Can only access its own virtual address space |
| Protection | No protection - errors can crash system | Protected - errors confined to process |
| CPU Mode | Privileged mode (Ring 0) | Unprivileged mode (Ring 3) |
| Code Running | Kernel code, drivers, essential services | Applications, libraries, utilities |
| Interrupt Handling | Can handle hardware interrupts directly | Cannot handle interrupts |
Crossing the Boundary: System Calls
System calls are the controlled interface between user space and kernel space, providing a secure way for applications to request kernel services.
(e.g., fopen()) UL->>SC: Invoke system call
(e.g., open()) Note over UL,SC: CPU switches to kernel mode SC->>K: Execute kernel function K->>SC: Return result Note over SC,UL: CPU switches back to user mode SC->>UL: Return to library UL->>UA: Return to application
Example: Tracing System Calls
We can observe system calls using the strace utility:
# Trace system calls made by the 'ls' command
$ strace ls
execve("/usr/bin/ls", ["ls"], 0x7ffc82dff800 /* 55 vars */) = 0
brk(NULL) = 0x55de6db64000
arch_prctl(0x3001 /* ARCH_??? */, 0x7fff4acaff00) = -1 EINVAL
access("/etc/ld.so.preload", R_OK) = -1 ENOENT
openat(AT_FDCWD, "/etc/ld.so.cache", O_RDONLY|O_CLOEXEC) = 3
...
openat(AT_FDCWD, ".", O_RDONLY|O_NONBLOCK|O_CLOEXEC|O_DIRECTORY) = 3
getdents64(3, /* 20 entries */, 32768) = 704
getdents64(3, /* 0 entries */, 32768) = 0
close(3) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 1), ...}) = 0
write(1, "file1.txt file2.txt folder1 f"..., 40) = 40
close(1) = 0
close(2) = 0
exit_group(0) = ?
+++ exited with 0 +++
This output shows how even a simple command like ls makes numerous system calls to interact with the kernel for operations like file access and directory reading.
Advanced Kernel Features
Kernel Modules
Kernel modules are dynamically loadable components that extend the kernel’s functionality without requiring a system reboot.
Module Management
Kernel modules are object files (.ko) that can be loaded and unloaded at runtime, providing a flexible way to add functionality to the kernel.
Key module management commands:
lsmod: List currently loaded modulesmodinfo: Display information about a modulemodprobe: Load a module and its dependenciesrmmod: Unload a moduleinsmod: Load a module directly (without dependency handling)
Modules are typically stored in /lib/modules/$(uname -r)/kernel/
Module Parameters
Modules can be configured through parameters at load time:
# Load module with custom parameters
$ sudo modprobe iwlwifi power_save=1 disable_11ax=0
# View current module parameters
$ systool -v -m iwlwifi
power_save = "1"
disable_11ax = "0"
# Set parameters through sysfs
$ echo 0 | sudo tee /sys/module/iwlwifi/parameters/power_save
Namespaces
Namespaces isolate system resources, forming the foundation for container technologies.
Types of Namespaces:
| Namespace | Resources Isolated | Example Command |
|---|---|---|
| PID | Process IDs | unshare --pid --fork bash |
| Network | Network interfaces, routing tables, firewall rules | ip netns add mynet |
| Mount | Mount points | unshare --mount bash |
| UTS | Hostname and domain name | unshare --uts bash |
| IPC | System V IPC objects, POSIX message queues | unshare --ipc bash |
| User | User and group IDs | unshare --map-root-user --user bash |
| Cgroup | Control group root directory | unshare --cgroup bash |
Control Groups (cgroups)
Control groups allow the kernel to allocate and limit resources among process groups.
Using cgroups
# Create a new cgroup for a database service
$ sudo cgcreate -g memory,cpu:database
# Set memory limit to 2GB
$ sudo cgset -r memory.limit_in_bytes=2G database
# Set CPU quota (40% of one CPU core)
$ sudo cgset -r cpu.cfs_quota_us=40000 database
$ sudo cgset -r cpu.cfs_period_us=100000 database
# Add a process to the cgroup
$ sudo cgclassify -g memory,cpu:database $(pgrep mysqld)
# Check resource usage
$ cat /sys/fs/cgroup/memory/database/memory.usage_in_bytes
Linux Capabilities
Capabilities break down the traditional root/non-root privilege binary into finer-grained permissions.
Working with Capabilities
# View capabilities of a process
$ getpcaps $$
Capabilities for `15632': = cap_chown,cap_dac_override,...
# View capabilities of a binary
$ getcap /usr/bin/ping
/usr/bin/ping = cap_net_raw+ep
# Add capabilities to a binary
$ sudo setcap cap_net_admin+ep /usr/local/bin/my_network_tool
# Run a process with specific capabilities
$ capsh --caps="cap_net_admin+ep" --
Performance Monitoring and Tracing
The Linux kernel provides sophisticated tools for monitoring and tracing system behavior.
Key Tracing Frameworks:
- ftrace: Function tracer built into the kernel
- perf: Performance analysis tool
- eBPF: Extended Berkeley Packet Filter for efficient in-kernel programmability
- SystemTap: Scripting language for kernel instrumentation
- LTTng: Linux Trace Toolkit, next generation
Example: Using perf for CPU profiling
# Record performance data for a command
$ perf record -F 99 -g ./my_application
# Analyze the recorded data
$ perf report
# Live monitoring of CPU events
$ perf top
# Count system-wide events for 10 seconds
$ perf stat -a sleep 10
Kernel Security Features
Security Mechanisms
Linux incorporates multiple layers of security within the kernel itself.
Core Security Features:
SELinux and AppArmor
These are Mandatory Access Control (MAC) systems that enforce security policies beyond traditional Unix permissions.
SELinux Example:
# Check if SELinux is enabled
$ getenforce
Enforcing
# View SELinux context of a file
$ ls -Z /etc/passwd
system_u:object_r:passwd_file_t:s0 /etc/passwd
# View SELinux context of a process
$ ps -Z -p $$
unconfined_u:unconfined_r:unconfined_t:s0-s0:c0.c1023 3842 pts/0 bash
AppArmor Example:
# Check AppArmor status
$ aa-status
apparmor module is loaded.
14 profiles are loaded.
13 profiles are in enforce mode.
1 profiles are in complain mode.
...
# Put profile in complain mode (log but don't block)
$ sudo aa-complain /usr/bin/firefox
# Put profile in enforce mode
$ sudo aa-enforce /etc/apparmor.d/usr.bin.firefox
Seccomp
Seccomp (secure computing mode) restricts the system calls that a process can make.
# Run a shell with only limited syscalls allowed
$ sudo docker run --security-opt seccomp=/path/to/seccomp.json alpine sh
# Example of a minimal seccomp filter in C
#include <stdio.h>
#include <seccomp.h>
#include <unistd.h>
int main() {
scmp_filter_ctx ctx;
// Initialize filter in whitelist mode
ctx = seccomp_init(SCMP_ACT_KILL);
// Allow minimal syscalls
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(read), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(write), 0);
seccomp_rule_add(ctx, SCMP_ACT_ALLOW, SCMP_SYS(exit), 0);
// Load the filter
seccomp_load(ctx);
printf("Seccomp filter loaded. Only read/write/exit syscalls allowed.\n");
// This execve call will be blocked
execve("/bin/ls", NULL, NULL);
return 0;
}
Kernel Monitoring and Tuning
The /proc Filesystem
The /proc filesystem provides a window into the kernel’s view of the system.
Key /proc Files:
/proc/cpuinfo: Detailed CPU information/proc/meminfo: Memory usage statistics/proc/loadavg: System load averages/proc/net/: Networking statistics and configuration/proc/sys/: Kernel parameters that can be tuned/proc/[pid]/: Information about specific processes/proc/interrupts: IRQ usage statistics/proc/filesystems: Supported filesystems/proc/diskstats: Disk I/O statistics/proc/version: Kernel version information
Kernel Parameters with sysctl
The sysctl interface allows viewing and modifying kernel parameters at runtime.
Example sysctl Commands:
# List all kernel parameters
$ sudo sysctl -a
# Get specific parameter
$ sysctl vm.swappiness
vm.swappiness = 60
# Set parameter temporarily (until reboot)
$ sudo sysctl -w vm.swappiness=10
# Make setting persistent
$ echo "vm.swappiness=10" | sudo tee -a /etc/sysctl.conf
$ sudo sysctl -p # Load settings from file
Common Kernel Tuning Parameters
| Parameter | Description | Typical Use Case |
|---|---|---|
vm.swappiness |
Controls how aggressively memory is swapped to disk | Lower for database servers (e.g., 10-30) to reduce disk I/O |
fs.file-max |
Maximum number of file handles | Increase for servers handling many connections |
net.core.somaxconn |
Maximum socket connection backlog | Increase for high-traffic web servers |
net.ipv4.tcp_fin_timeout |
How long to keep sockets in FIN-WAIT-2 state | Reduce to free up resources faster in high-connection environments |
kernel.pid_max |
Maximum process ID number | Increase for systems running many processes |
vm.dirty_ratio |
Percentage of memory that can be filled with dirty pages before flushing | Adjust for I/O-intensive workloads |
Performance Monitoring Tools
Essential Linux Performance Tools
- top/htop provides an interactive process viewer for real-time system monitoring.
- vmstat displays virtual memory statistics to help analyze memory usage patterns.
- iostat reports CPU and disk I/O statistics for performance analysis.
- mpstat shows multi-processor statistics across different CPU cores.
- sar serves as a comprehensive system activity reporter that maintains historical data for trend analysis.
- perf offers detailed performance analysis with CPU profiling capabilities for in-depth optimization.
- strace traces system calls and signals to debug application behavior.
- tcpdump functions as a network packet analyzer for traffic inspection and troubleshooting.
- netstat/ss provide network statistics and connection information.
- ftrace operates as a kernel function tracer for low-level system analysis and debugging.
Example: Using sar to Monitor System Activity
# Install sar (if not already available)
$ sudo apt install sysstat
# Enable data collection
$ sudo systemctl enable sysstat
$ sudo systemctl start sysstat
# View CPU statistics from today
$ sar -u
# View memory usage with 2-second intervals for 5 samples
$ sar -r 2 5
# View historical disk I/O from yesterday
$ sar -b -f /var/log/sysstat/sa$(date -d yesterday +%d)
Kernel Compilation and Customization
For advanced users, compiling a custom kernel provides maximum control over the system.
Why Compile a Custom Kernel?
- Add specific features not in the standard kernel
- Remove unnecessary components to reduce size
- Optimize for specific hardware
- Apply custom patches
- Learn about kernel internals
Basic Kernel Compilation Process
# Install required packages
$ sudo apt install build-essential libncurses-dev bison flex libssl-dev libelf-dev
# Download kernel source
$ wget https://cdn.kernel.org/pub/linux/kernel/v5.x/linux-5.15.tar.xz
$ tar xf linux-5.15.tar.xz
$ cd linux-5.15
# Copy current configuration as starting point
$ cp /boot/config-$(uname -r) .config
# Customize configuration
$ make menuconfig
# Compile the kernel (using all CPU cores)
$ make -j$(nproc)
# Install modules
$ sudo make modules_install
# Install the kernel
$ sudo make install
# Update bootloader
$ sudo update-grub
Kernel Configuration Options
The kernel has thousands of configuration options. Some important categories:
- Processor type and features: CPU-specific optimizations
- Power management: Options for saving power
- Networking support: Protocols and hardware support
- Device drivers: Hardware-specific drivers
- File systems: Support for various file systems
- Security options: Security features and hardening
- Virtualization: Hypervisor and guest support
Key Points
-
Core Functions
- Process scheduling and management
- Memory management with virtual memory
- Device drivers for hardware interaction
- File systems for data organization
- Networking stack for communications -
Architecture
- Monolithic design with modular capabilities
- Kernel space/user space separation
- System calls as the interface between spaces
- Preemptible for better responsiveness -
Advanced Features
- Loadable kernel modules for extensibility
- Namespaces and cgroups for resource isolation
- Security mechanisms like SELinux, capabilities
- Rich monitoring and tracing capabilities

Comments