14 min to read
Implementing Redis Redlock on Kubernetes — A Complete Guide to Distributed Locks
Principles of Redlock, safe implementation patterns on Kubernetes, operational pitfalls, and alternatives
Overview
Concurrency control is one of the trickiest problems in distributed systems.
When multiple instances contend for the same resource, you need a reliable locking mechanism to maintain data consistency and prevent race conditions.
A naive single Redis instance with SET NX is unsafe under network partitions, instance failures, and clock drift. To address these risks, Redis creator Salvatore Sanfilippo proposed the Redlock algorithm.
This post covers how Redlock works, safe implementation patterns on Kubernetes, must-have operational checks,
and how Redlock compares to DB- and Consul/etcd-based locking — all from a production perspective.
This guide targets teams operating Redis-based distributed locks reliably in on-premises or hybrid Kubernetes environments. It focuses on concepts, design, and operations — without code snippets.
What is Redlock?
Key ideas
- A client must acquire the lock on a majority (N/2+1) of independent Redis instances to succeed.
- Locks use a TTL and a unique token to validate ownership and guarantee automatic release.
- Compute effective validity by accounting for clock drift, and release any partially acquired locks on failure.
Why multiple instances?
- Eliminate single points of failure (SPOF)
- Prevent split-brain/effective double-locks during network partitions
- Gain tolerance to inter-node clock skew
How Redlock Works (Deep dive)
1) Acquire
- Attempt to acquire the lock concurrently across instances with a unique token and TTL.
- Sum the elapsed time and compute the effective validity relative to the TTL.
def acquire_lock(resource_name, ttl):
start_time = current_time()
successful_locks = 0
unique_value = generate_unique_id()
# To all Redis instances at the same time
for redis_instance in redis_instances:
if redis_instance.set(resource_name, unique_value, px=ttl, nx=True):
successful_locks += 1
elapsed_time = current_time() - start_time
drift = (ttl * 0.01) + 2 # Clock drift calibration
# Success conditions: majority + valid time left
if successful_locks >= (len(redis_instances) / 2 + 1):
validity_time = ttl - elapsed_time - drift
if validity_time > 0:
return True, validity_time
# Unlock on all instances in case of failure
release_lock(resource_name, unique_value)
return False, 0
2) Success conditions
- Majority of instances acquired
- TTL − (elapsed + drift) > 0
3) Release
- Delete only if the stored token matches the owner token (atomicity)
- On failure/timeout, release any partial acquisitions
## Lua script
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
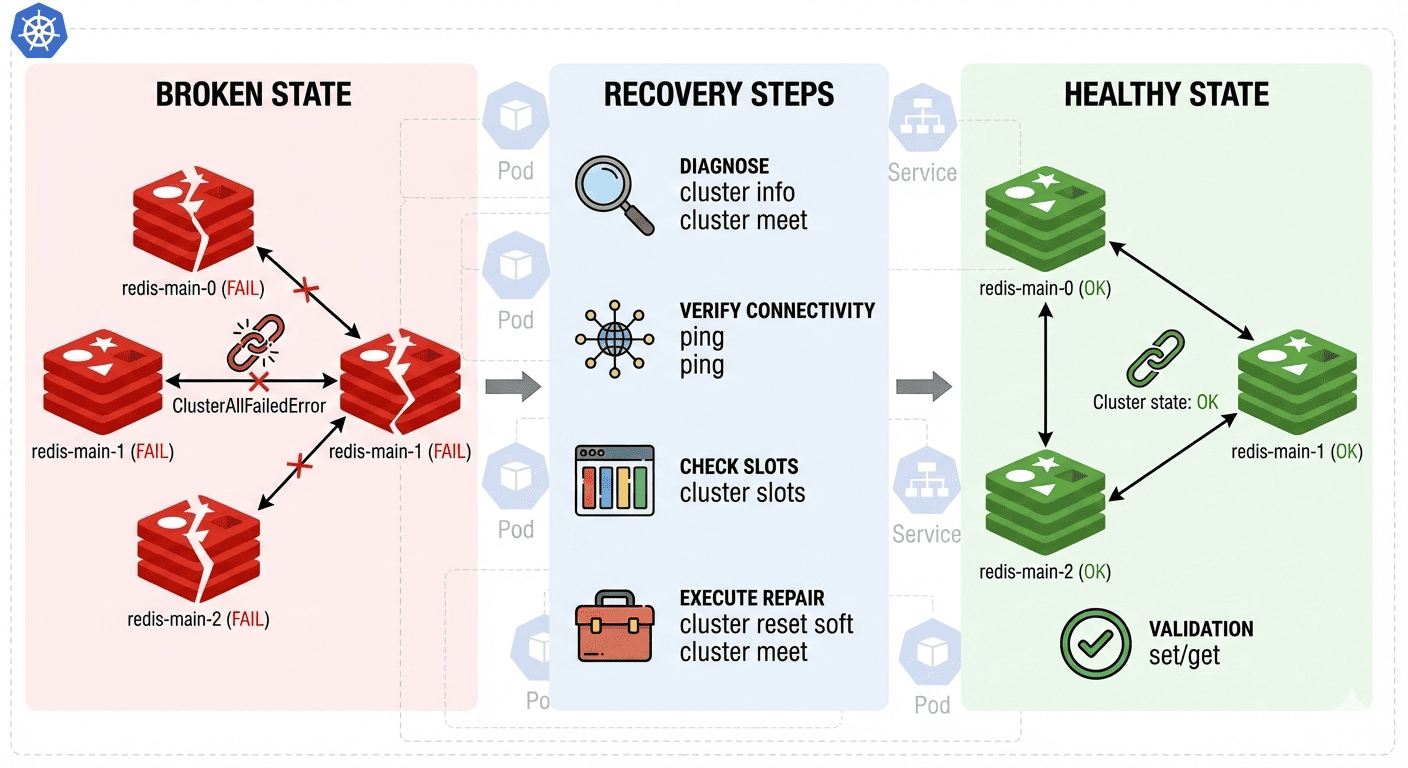
Common Kubernetes Pitfalls
Many teams assume that deploying Redis as a StatefulSet with a Headless Service makes Redlock safe by default. It does not, for several reasons:
- Headless DNS limitations: Even with multiple A records, many Redis clients use only the first IP.
- Lack of independence: Co-locating pods on the same node/rack/storage overlaps failure domains.
- Client awareness: Clients may not treat pods as distinct, independently monitored instances.
Correct Implementation Patterns (Kubernetes)
Method 1 — Per-pod Services (recommended)
- Expose a dedicated Service per Redis pod to create clear, stable endpoints.
- The application creates independent connections to each Service for the Redlock cluster.
apiVersion: v1
kind: Service
metadata:
name: redis-0
spec:
selector:
app: redis-cluster
statefulset.kubernetes.io/pod-name: redis-cluster-0
ports:
- port: 6379
targetPort: 6379
---
apiVersion: v1
kind: Service
metadata:
name: redis-1
spec:
selector:
app: redis-cluster
statefulset.kubernetes.io/pod-name: redis-cluster-1
ports:
- port: 6379
targetPort: 6379
---
apiVersion: v1
kind: Service
metadata:
name: redis-2
spec:
selector:
app: redis-cluster
statefulset.kubernetes.io/pod-name: redis-cluster-2
ports:
- port: 6379
targetPort: 6379
Method 2 — Pod anti-affinity
- Enforce spread policies to avoid co-scheduling on the same node/rack.
- Maximize independence across failure domains (node/power/network/storage).
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster
spec:
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis-cluster
topologyKey: kubernetes.io/hostname
Method 3 — DNS-based dynamic discovery
- Periodically resolve headless endpoints to refresh the connection pool dynamically.
- Tune connection/retry/timeout policies conservatively for Redlock assumptions.
const dns = require('dns').promises;
async function getRedisInstances() {
const addresses = await dns.lookup('redis-service', { all: true });
return addresses.map(addr => ({
host: addr.address,
port: 6379
}));
}
async function createRedlock() {
const instances = await getRedisInstances();
return new Redlock(instances.map(config => new Redis(config)));
}
Real-world Implementation Patterns (No code)
Application layer (e.g., Node.js, Java)
- Use the same lock key across at least three independent Redis instances to achieve majority consensus.
- Maintain separate event/error handlers per connection and observe connection health independently.
- Configure Redlock client retry counts/delays/jitter and drift factors explicitly.
Node
const Redis = require('ioredis');
const Redlock = require('redlock');
class RedlockService {
constructor() {
// Connections using per-pod Services
this.redisClients = [
new Redis({
host: 'redis-0.default.svc.cluster.local',
port: 6379,
retryDelayOnFailover: 100,
maxRetriesPerRequest: 3
}),
new Redis({
host: 'redis-1.default.svc.cluster.local',
port: 6379,
retryDelayOnFailover: 100,
maxRetriesPerRequest: 3
}),
new Redis({
host: 'redis-2.default.svc.cluster.local',
port: 6379,
retryDelayOnFailover: 100,
maxRetriesPerRequest: 3
})
];
this.redlock = new Redlock(this.redisClients, {
retryCount: 3,
retryDelay: 200,
retryJitter: 200,
driftFactor: 0.01,
clockDriftMs: 2
});
this.setupEventHandlers();
}
setupEventHandlers() {
this.redisClients.forEach((client, index) => {
client.on('connect', () => {
console.log(`Redis-${index} connected`);
});
client.on('error', (err) => {
console.error(`Redis-${index} error:`, err.message);
});
});
this.redlock.on('clientError', (err) => {
console.error('Redlock client error:', err);
});
}
async acquireLock(resource, ttl = 10000) {
try {
console.log(`Attempting to acquire lock: ${resource}`);
const lock = await this.redlock.acquire([resource], ttl);
console.log(`Lock acquired: ${resource}`);
return lock;
} catch (error) {
console.error(`Failed to acquire lock: ${resource}`, error.message);
throw error;
}
}
async releaseLock(lock) {
try {
await lock.release();
console.log(`Lock released: ${lock.resources}`);
} catch (error) {
console.error(`Failed to release lock:`, error.message);
throw error;
}
}
}
// Usage example
async function criticalSection() {
const redlockService = new RedlockService();
try {
const lock = await redlockService.acquireLock('user-action-123', 15000);
try {
// Work performed in critical section
console.log('Performing critical work...');
await performCriticalOperation();
console.log('Work completed');
} finally {
await redlockService.releaseLock(lock);
}
} catch (error) {
console.error('Work failed:', error.message);
}
}
Java (Redisson)
import org.redisson.Redisson;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
@Service
public class RedlockService {
private final RedissonClient redissonClient;
public RedlockService() {
Config config = new Config();
config.useReplicatedServers()
.addNodeAddress("redis://redis-0.default.svc.cluster.local:6379")
.addNodeAddress("redis://redis-1.default.svc.cluster.local:6379")
.addNodeAddress("redis://redis-2.default.svc.cluster.local:6379");
this.redissonClient = Redisson.create(config);
}
public boolean executeWithLock(String lockName, int ttlSeconds, Runnable task) {
RLock lock = redissonClient.getLock(lockName);
try {
if (lock.tryLock(10, ttlSeconds, TimeUnit.SECONDS)) {
try {
log.info("Lock acquired: {}", lockName);
task.run();
return true;
} finally {
lock.unlock();
log.info("Lock released: {}", lockName);
}
} else {
log.warn("Failed to acquire lock: {}", lockName);
return false;
}
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
log.error("Interrupted while acquiring lock: {}", lockName, e);
return false;
}
}
}
Lock lifecycle
- Set TTL to 2–3× expected work time (including buffer).
- For long-running work, include lock extend/refresh and define rollback/retry on failure.
- Release locks only after verifying the ownership token (avoid cross-release).
Operations Checklist
1) Clock synchronization
- Enable NTP/Chrony on all nodes and build a drift monitoring dashboard.
# Check NTP synchronization state
chrony sources -v
# Reduce clock drift
echo "server time.google.com iburst" >> /etc/chrony.conf
systemctl restart chronyd
2) TTL/timeout policies
- Keep connection/command timeouts low; use short, shallow retries for fast failure.
- Derive TTLs from workload profiling, including peak scenarios.
const expectedWorkTime = 5000; // 5 seconds
const safetyMargin = 2;
const ttl = expectedWorkTime * safetyMargin; // 10 seconds
3) Observability
- Collect and alert on the following metrics:
| Metric | Purpose |
|---|---|
| redlock_acquire_success_total | Lock acquisition success trend |
| redlock_acquire_failure_total | Diagnose lock acquisition failures |
| redlock_acquire_duration_seconds | Distribution of acquisition latency |
| redlock_validity_time_remaining | Observe remaining validity time |
| redis_connection_failures_total | Per-instance connection stability |
4) Failure scenarios
- Provide safe abort/rollback paths when lock extension fails.
- After partial success/failure, release on all instances to restore consistency.
- Rehearse network partitions, node failures, and clock skew scenarios in advance.
Alternatives and Comparison
vs. Database-based locking
| Aspect | Redlock | Database Lock |
|---|---|---|
| Performance | Very fast | Relatively slower |
| Complexity | Medium | Simple |
| Consistency | Eventual | Strong (transactional) |
| Failure recovery | Automatic TTL expiry | Manual/transactional release |
vs. Consul/etcd-based locking
| Aspect | Redlock | Consul/etcd |
|---|---|---|
| Infrastructure complexity | Low | High |
| Performance | Very fast | Fast |
| Consensus | Majority vote | Raft |
| Ecosystem | Redis-centric | Microservices/Orchestration |
When to Use Redlock
Well-suited for
- Real-time systems where very low latency and high throughput matter
- Teams that already operate Redis with low operational overhead
- Simple lock semantics (acquire/extend/release) without stringent consensus requirements
Avoid when
- Domains requiring strict strong consistency (e.g., finance)
- Environments with frequent partitions or poor time synchronization
- Workloads where consensus correctness is paramount (prefer Raft-based approaches)
Conclusion: Safe Redlock on Kubernetes
Redlock is elegant, but correct implementation is everything.
On Kubernetes, a StatefulSet alone is insufficient — you need independent access paths to each Redis instance and separation of failure domains.
Combine that with clock sync, TTL/timeout discipline, observability, and failure drills to achieve operational reliability. Redlock is not a universal answer; depending on requirements, DB- or Consul/etcd-based locking may be a better fit.
References
- Redis Redlock official documentation
- Martin Kleppmann’s critique of Redlock
- Kubernetes StatefulSet guide
- Redis clustering best practices
- Kubernetes Storage Concepts

Comments