13 min to read
Understanding Kubernetes Endpoints and EndpointSlices
A comprehensive guide to service discovery mechanisms in Kubernetes
Understanding Kubernetes Endpoints and EndpointSlices
In Kubernetes, services route traffic to pods, but how does a service know which pods to target?
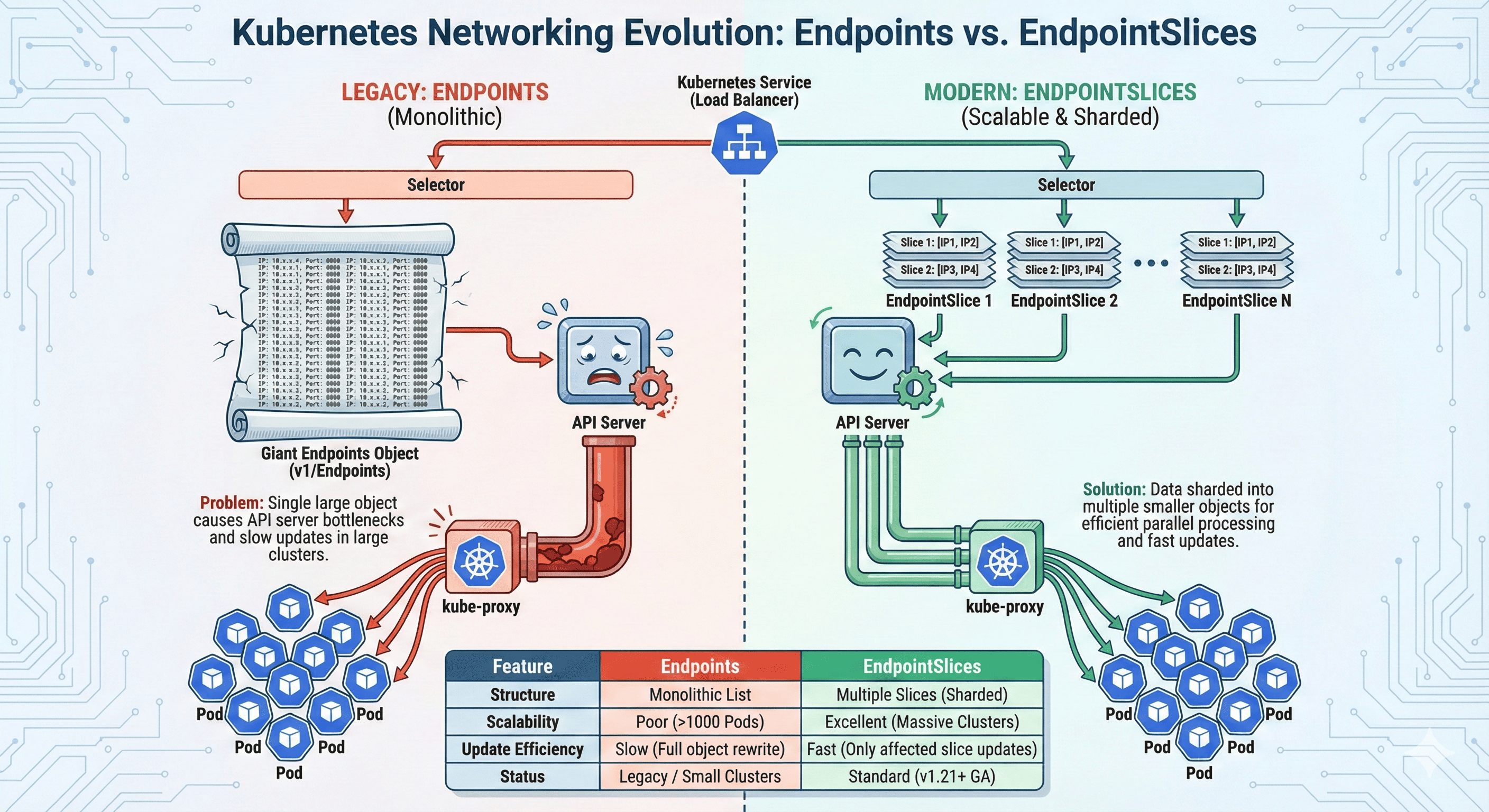
This is where Endpoints and EndpointSlices come in - they store the mapping between services and the actual pods that receive the traffic.
Understanding these resources is crucial for managing large-scale Kubernetes environments effectively.
What are Endpoints?
Endpoint Basics
An Endpoint resource in Kubernetes is essentially an address book that contains the IP addresses and ports of all pods matching a service’s selector. When you create a service, Kubernetes automatically:
- Creates a corresponding Endpoint object with the same name as the service
- Tracks pods matching the service’s selector
- Updates the Endpoint object whenever pods are created, deleted, or modified
- Uses this information to direct traffic to the right destinations
Endpoints Example
kind: Endpoints
apiVersion: v1
metadata:
name: my-service
subsets:
- addresses:
- ip: 10.233.65.100
- ip: 10.233.65.101
- ip: 10.233.65.102
ports:
- port: 8080
What are EndpointSlices?
EndpointSlices are an evolution of the Endpoints concept, designed to address scalability issues in large Kubernetes clusters. They divide the network endpoint information into multiple smaller resources, providing better performance and scalability.
EndpointSlice Example
kind: EndpointSlice
apiVersion: discovery.k8s.io/v1
metadata:
name: my-service-abc
labels:
kubernetes.io/service-name: my-service
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 8080
endpoints:
- addresses:
- "10.233.65.100"
- "10.233.65.101"
conditions:
ready: true
nodeName: node-1
---
kind: EndpointSlice
apiVersion: discovery.k8s.io/v1
metadata:
name: my-service-xyz
labels:
kubernetes.io/service-name: my-service
addressType: IPv4
ports:
- name: http
protocol: TCP
port: 8080
endpoints:
- addresses:
- "10.233.65.102"
conditions:
ready: true
nodeName: node-2
Key Features of EndpointSlices
EndpointSlices improve upon Endpoints in several ways:
- Sliced Storage: Divides endpoints into multiple smaller resources
- Enhanced Fields: Includes node name, topology, and conditions
- Scalability: Each slice typically contains up to 100 endpoints
- Multiple Address Types: Supports IPv4, IPv6, and FQDN
- Better Update Performance: Only affected slices need to be updated
Evolution: From Endpoints to EndpointSlices
| Kubernetes Version | EndpointSlice Status | Description |
|---|---|---|
| 1.16 | Alpha | Initial introduction as an experimental feature |
| 1.17 | Beta | Improved stability and performance |
| 1.19 | Beta | Added topology aware hints |
| 1.21 | GA (Stable) | Feature declared production-ready |
| 1.22+ | Default | kube-proxy prefers EndpointSlices by default |
Why EndpointSlices Replaced Endpoints
The transition from Endpoints to EndpointSlices was driven by real-world scalability problems encountered in large Kubernetes clusters. Understanding these challenges helps appreciate why this evolution was necessary.
The Problems with Endpoints
As Kubernetes clusters grew in size, several limitations of the original Endpoints implementation became apparent:
- Large Object Size: Services with thousands of pods created extremely large Endpoint objects
- Update Inefficiency: Any change required updating the entire Endpoint object
- API Server Load: Large updates put significant pressure on the API server
- Watch Event Size: Each update generated large watch events for all observers
- kube-proxy Performance: Processing large Endpoint objects consumed significant resources
How EndpointSlices Solve These Problems
| Problem | EndpointSlice Solution |
|---|---|
| Large Objects | Splits endpoints into multiple smaller objects (typically 100 endpoints per slice) |
| Update Inefficiency | Only updates the affected slices, not all endpoints |
| API Server Load | Reduces pressure with smaller, more targeted updates |
| Watch Event Size | Generates smaller watch events, improving client performance |
| kube-proxy Performance | Processes smaller chunks of data, reducing resource consumption |
Detailed Comparison
Let’s compare Endpoints and EndpointSlices across multiple dimensions to better understand their differences and capabilities.
| Feature | Endpoints | EndpointSlices |
|---|---|---|
| API Version | v1 (core) | discovery.k8s.io/v1 |
| Structure | Single object per service | Multiple objects per service |
| Size Limit | No internal limits | ~100 endpoints per slice |
| Address Types | IPv4 only | IPv4, IPv6, FQDN |
| Node Information | Not included | Includes nodeName |
| Topology | Not supported | Supports topology hints |
| Readiness | NotReadyAddresses field | Structured conditions |
| Performance at Scale | Poor | Good |
How kube-proxy Uses Endpoints/EndpointSlices
The kube-proxy component is responsible for implementing the Kubernetes Service concept at the network level. Understanding how it interacts with Endpoints and EndpointSlices helps grasp the full picture of service discovery in Kubernetes.
kube-proxy Configuration
In modern Kubernetes versions, kube-proxy is configured to use EndpointSlices by default. This is controlled by the EndpointSliceProxying feature gate:
# kube-proxy ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: kube-proxy
namespace: kube-system
data:
config.conf: |-
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
mode: "iptables"
featureGates:
EndpointSliceProxying: true # Default is true in Kubernetes 1.22+
Performance Comparison at Scale
The true benefits of EndpointSlices become apparent as clusters scale. Let’s examine how performance differs between Endpoints and EndpointSlices under various conditions.
| Cluster Size | Endpoints Performance | EndpointSlices Performance |
|---|---|---|
| Small (< 100 pods/service) |
Good - No significant overhead | Good - Slight overhead from multiple objects |
| Medium (100-500 pods/service) |
Acceptable - Some load on API server during updates | Good - Balanced distribution across slices |
| Large (500-1000 pods/service) |
Poor - Noticeable API server load, latency during updates | Good - Updates isolated to affected slices |
| Very Large (1000+ pods/service) |
Critical - Significant performance impact, potential timeouts | Good - Consistent performance regardless of scale |
At large scale, the differences become critical:
- API Server CPU Usage: Up to 70% reduction with EndpointSlices
- Memory Usage: Better memory efficiency for kube-proxy
- Update Latency: Significant improvement in service update times
- Control Plane Responsiveness: Less impact during large service changes
These improvements are particularly important for clusters with large, dynamic workloads where pods are frequently created and destroyed.
Practical Examples
Let’s walk through some practical examples of how Endpoints and EndpointSlices are created and managed in a Kubernetes cluster.
Example 1: Creating a Service and Observing Endpoints
# Create a deployment with 3 replicas
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
---
# Create a service for the deployment
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: 80
After applying this YAML, Kubernetes automatically creates:
- An Endpoint object named
nginx-service - EndpointSlice object(s) with the label
kubernetes.io/service-name: nginx-service
You can inspect these resources with:
kubectl get endpoints nginx-service -o yamlkubectl get endpointslices -l kubernetes.io/service-name=nginx-service -o yaml
Example 2: Scaling the Deployment
When you scale the deployment up or down, you can observe how differently Endpoints and EndpointSlices are updated:
# Scale to 10 replicas
kubectl scale deployment nginx-deployment --replicas=10
# Observe changes
kubectl get endpoints nginx-service -o yaml
kubectl get endpointslices -l kubernetes.io/service-name=nginx-service
For EndpointSlices: Multiple smaller updates
Managing and Troubleshooting
When working with Kubernetes services, understanding how to inspect and troubleshoot Endpoints and EndpointSlices is essential.
Common Commands
| Command | Purpose |
|---|---|
kubectl get endpoints |
List all Endpoints in the current namespace |
kubectl get endpointslices |
List all EndpointSlices in the current namespace |
kubectl describe endpoints <name> |
Show detailed information about a specific Endpoint |
kubectl describe endpointslice <name> |
Show detailed information about a specific EndpointSlice |
kubectl get endpointslices -l kubernetes.io/service-name=<service-name> |
Find all EndpointSlices for a specific service |
Troubleshooting Service Connectivity Issues
When services aren't routing traffic correctly, check these common causes:
- Empty Endpoints: No pods match the service selector
- Pod Not Ready: Pods exist but aren't in ready state
- Port Mismatch: Service port and pod containerPort don't match
- Network Policy: Network policies blocking traffic
- kube-proxy Issues: kube-proxy not running or misconfigured
# Check if endpoints exist for a service
kubectl get endpoints my-service
# If endpoints exist but service still doesn't work, check pod readiness
kubectl get pods -l app=my-app -o wide
# Examine EndpointSlices for more details
kubectl get endpointslices -l kubernetes.io/service-name=my-service -o yaml
# Check kube-proxy logs for issues
kubectl logs -n kube-system -l k8s-app=kube-proxy
Best Practices
Based on the evolution from Endpoints to EndpointSlices, here are some best practices for managing service discovery in Kubernetes.
-
Use Modern Kubernetes Versions
- Kubernetes 1.21+ uses EndpointSlices by default
- Ensures optimal performance for service discovery -
Service Design
- Avoid creating services with extremely large numbers of pods
- Consider using multiple smaller services rather than one giant service
- Use appropriate labels for effective service targeting -
Monitoring and Alerting
- Monitor kube-proxy resource usage
- Track EndpointSlice reconciliation metrics
- Alert on EndpointSlice controller lag -
Resource Planning
- Account for additional EndpointSlice objects in etcd capacity planning
- Ensure adequate CPU resources for the endpoint-slice controller
- Consider EndpointSlice cache size in kube-proxy memory allocation
Future Developments
Service discovery in Kubernetes continues to evolve. Several enhancements to EndpointSlices are under development or consideration.
| Feature | Description |
|---|---|
| Enhanced Topology Awareness | Improved routing to endpoints based on network topology and node proximity |
| Custom Distribution | Allow custom strategies for distributing endpoints across slices |
| Endpoint Health Integration | Better integration with health checking mechanisms |
| Gateway Integration | Integration with Gateway API for more sophisticated traffic routing |
| Endpoint Identity | Enhanced security with endpoint identity verification |
Summary
-
Endpoints vs EndpointSlices
- Endpoints: Original implementation, one object per service
- EndpointSlices: Scalable implementation, multiple objects per service -
Performance Impact
- Small clusters: Minimal difference
- Large clusters: EndpointSlices provide significant performance benefits -
Adoption Timeline
- Introduced: Kubernetes 1.16 (Alpha)
- Stable: Kubernetes 1.21
- Default: Kubernetes 1.22+ -
Managed Kubernetes
- Most managed Kubernetes services now use EndpointSlices by default
- Check provider documentation for version-specific details

Comments