25 min to read
Enterprise Kubernetes Workload Resources - Production Deployment Patterns
Advanced orchestration patterns for Deployments, StatefulSets, DaemonSets, Jobs, and CronJobs in enterprise environments

Enterprise Kubernetes Workload Resources
In enterprise environments, container orchestration extends far beyond basic deployment patterns. Modern organizations require sophisticated workload management that encompasses security hardening, compliance frameworks, high availability patterns, and operational excellence.
This comprehensive guide explores enterprise-grade Kubernetes workload resources, providing the depth and practical insights needed for production-ready implementations.
Kubernetes workload resources form the foundation of container orchestration, each serving distinct purposes in enterprise architectures.
From stateless microservices requiring rapid scaling to stateful databases demanding persistent identity, from system-level monitoring agents to batch processing workflows - understanding when and how to leverage each resource type is crucial for building resilient, scalable, and secure enterprise platforms.
Enterprise Architecture Foundation
Modern enterprise Kubernetes environments demand sophisticated workload patterns that address multi-tenancy, security compliance, disaster recovery, and operational excellence. Each workload resource type serves specific enterprise requirements:
Application Workloads
- Deployments: Stateless microservices, API gateways, frontend applications
- StatefulSets: Databases, message queues, distributed storage systems
Platform Workloads
- DaemonSets: Security agents, monitoring collectors, network plugins
- Jobs/CronJobs: Data processing pipelines, backup operations, compliance scanning
Enterprise Integration Points
- Service mesh integration for traffic management and security
- Persistent storage orchestration for stateful workloads
- Comprehensive observability and monitoring integration
- Policy enforcement and compliance frameworks
Enterprise Workload Resource Overview
Enterprise Kubernetes deployments require sophisticated workload management patterns that address scalability, security, compliance, and operational excellence. This section provides a comprehensive overview of core workload resources and their enterprise applications.
Primary Workload Resources:
- Deployments & ReplicaSets: Stateless application orchestration with advanced scaling and update strategies
- StatefulSets: Stateful application management with persistent identity and ordered operations
- DaemonSets: Node-level system services and infrastructure components
- Jobs & CronJobs: Batch processing and scheduled task execution with enterprise scheduling patterns
Enterprise Requirements Integration:
- High availability and disaster recovery patterns
- Security policy enforcement and compliance frameworks
- Resource governance and cost optimization
- Observability and monitoring integration
- Multi-environment deployment strategies
Enterprise Deployments, ReplicaSets, and Pods
Enterprise deployments require sophisticated orchestration patterns that ensure high availability, security compliance, and operational excellence. The three-tier hierarchy of Deployments → ReplicaSets → Pods provides enterprise-grade abstraction layers enabling advanced features like canary deployments, blue-green releases, and automated rollback mechanisms.
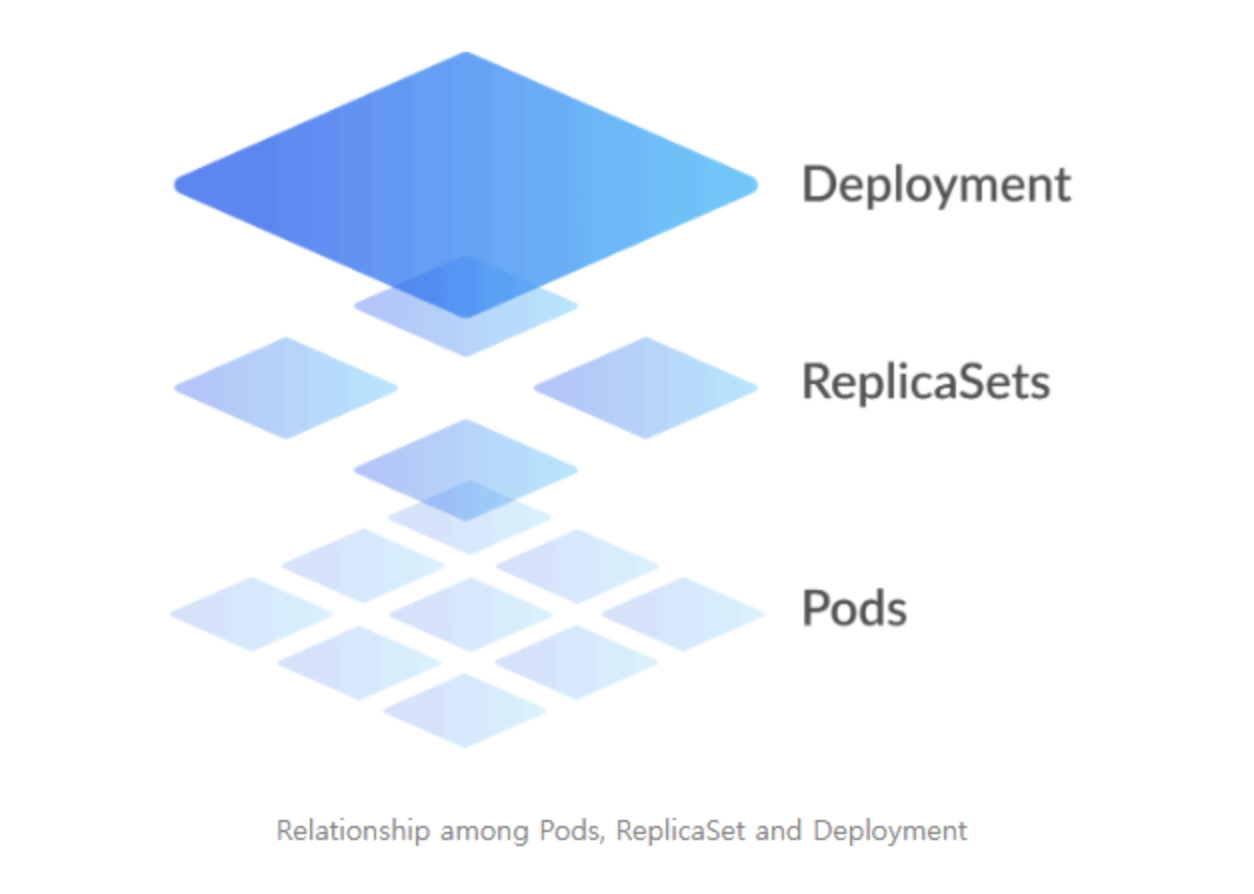
1. Enterprise Pod Specifications
Pods serve as the fundamental execution units in enterprise Kubernetes environments, requiring sophisticated configuration for security, resource management, and observability integration.
apiVersion: v1
kind: Pod
metadata:
name: enterprise-nginx-pod
labels:
app: nginx
version: v1.21.6
tier: frontend
environment: production
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9113"
vault.hashicorp.com/agent-inject: "true"
vault.hashicorp.com/role: "nginx-role"
spec:
securityContext:
runAsNonRoot: true
runAsUser: 101
fsGroup: 101
seccompProfile:
type: RuntimeDefault
serviceAccountName: nginx-service-account
containers:
- name: nginx
image: nginx:1.21.6-alpine
ports:
- containerPort: 8080
name: http
protocol: TCP
- containerPort: 9113
name: metrics
protocol: TCP
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
resources:
requests:
cpu: 100m
memory: 128Mi
ephemeral-storage: 1Gi
limits:
cpu: 500m
memory: 256Mi
ephemeral-storage: 2Gi
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 3
volumeMounts:
- name: nginx-config
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
readOnly: true
- name: cache-volume
mountPath: /var/cache/nginx
- name: run-volume
mountPath: /var/run
volumes:
- name: nginx-config
configMap:
name: nginx-config
defaultMode: 0644
- name: cache-volume
emptyDir: {}
- name: run-volume
emptyDir: {}
nodeSelector:
kubernetes.io/arch: amd64
node.kubernetes.io/instance-type: m5.large
tolerations:
- key: "node.kubernetes.io/not-ready"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 300
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 300
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
Enterprise Pod Characteristics:
- Security Hardening: Non-root execution, read-only filesystems, dropped capabilities
- Resource Governance: Comprehensive resource requests and limits with ephemeral storage
- Observability Integration: Prometheus metrics, health checks, structured logging
- High Availability: Anti-affinity rules, tolerations for node failures
- Compliance: Security contexts, service account integration, audit logging
2. Enterprise ReplicaSets
ReplicaSets provide enterprise-grade pod lifecycle management with advanced scheduling, resource governance, and failure recovery patterns designed for production workloads.
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: enterprise-nginx-replicaset
labels:
app: nginx
version: v1.21.6
tier: frontend
spec:
replicas: 5
selector:
matchLabels:
app: nginx
version: v1.21.6
template:
metadata:
labels:
app: nginx
version: v1.21.6
tier: frontend
annotations:
cluster-autoscaler.kubernetes.io/safe-to-evict: "true"
prometheus.io/scrape: "true"
prometheus.io/port: "9113"
spec:
securityContext:
runAsNonRoot: true
runAsUser: 101
fsGroup: 101
containers:
- name: nginx
image: nginx:1.21.6-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 256Mi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
priorityClassName: high-priority
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: nginx
- maxSkew: 1
topologyKey: kubernetes.io/hostname
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: nginx
Enterprise ReplicaSet Features:
- High Availability: Multi-zone distribution with topology spread constraints
- Resource Management: Priority classes and comprehensive resource governance
- Security Compliance: Pod security standards and security contexts
- Observability: Integrated metrics and monitoring annotations
- Operational Excellence: Cluster autoscaler integration and eviction policies
3. Enterprise Deployments
Deployments represent the pinnacle of enterprise container orchestration, providing sophisticated update strategies, rollback capabilities, and integration with enterprise CI/CD pipelines.
apiVersion: apps/v1
kind: Deployment
metadata:
name: enterprise-nginx-deployment
labels:
app: nginx
version: v1.21.6
component: frontend
annotations:
deployment.kubernetes.io/revision: "1"
kubernetes.io/change-cause: "Initial deployment with enterprise configuration"
spec:
replicas: 5
revisionHistoryLimit: 10
progressDeadlineSeconds: 600
selector:
matchLabels:
app: nginx
version: v1.21.6
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 25%
maxUnavailable: 25%
template:
metadata:
labels:
app: nginx
version: v1.21.6
component: frontend
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9113"
prometheus.io/path: "/metrics"
vault.hashicorp.com/agent-inject: "true"
vault.hashicorp.com/agent-inject-secret-config: "secret/nginx/config"
spec:
securityContext:
runAsNonRoot: true
runAsUser: 101
fsGroup: 101
seccompProfile:
type: RuntimeDefault
serviceAccountName: nginx-service-account
imagePullSecrets:
- name: enterprise-registry-secret
containers:
- name: nginx
image: registry.enterprise.com/nginx:1.21.6-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
name: http
protocol: TCP
- containerPort: 9113
name: metrics
protocol: TCP
env:
- name: ENVIRONMENT
value: "production"
- name: LOG_LEVEL
value: "info"
- name: OTEL_EXPORTER_OTLP_ENDPOINT
value: "http://jaeger-collector.observability:14268/api/traces"
resources:
requests:
cpu: 250m
memory: 256Mi
ephemeral-storage: 1Gi
limits:
cpu: 1000m
memory: 512Mi
ephemeral-storage: 2Gi
securityContext:
allowPrivilegeEscalation: false
readOnlyRootFilesystem: true
capabilities:
drop:
- ALL
add:
- NET_BIND_SERVICE
livenessProbe:
httpGet:
path: /health
port: 8080
scheme: HTTP
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
failureThreshold: 3
successThreshold: 1
readinessProbe:
httpGet:
path: /ready
port: 8080
scheme: HTTP
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 3
failureThreshold: 3
successThreshold: 1
startupProbe:
httpGet:
path: /startup
port: 8080
scheme: HTTP
initialDelaySeconds: 10
periodSeconds: 10
timeoutSeconds: 3
failureThreshold: 30
successThreshold: 1
volumeMounts:
- name: nginx-config
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
readOnly: true
- name: cache-volume
mountPath: /var/cache/nginx
- name: run-volume
mountPath: /var/run
- name: log-volume
mountPath: /var/log/nginx
- name: nginx-exporter
image: nginx/nginx-prometheus-exporter:0.10.0
args:
- -nginx.scrape-uri=http://localhost:8080/stub_status
ports:
- containerPort: 9113
name: metrics
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 100m
memory: 128Mi
volumes:
- name: nginx-config
configMap:
name: nginx-config
defaultMode: 0644
- name: cache-volume
emptyDir:
sizeLimit: 1Gi
- name: run-volume
emptyDir:
sizeLimit: 100Mi
- name: log-volume
emptyDir:
sizeLimit: 2Gi
nodeSelector:
kubernetes.io/arch: amd64
node.kubernetes.io/instance-type: m5.xlarge
tolerations:
- key: "node.kubernetes.io/not-ready"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 300
- key: "node.kubernetes.io/unreachable"
operator: "Exists"
effect: "NoExecute"
tolerationSeconds: 300
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- nginx
topologyKey: kubernetes.io/hostname
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: node-type
operator: In
values:
- compute-optimized
priorityClassName: high-priority
topologySpreadConstraints:
- maxSkew: 1
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: nginx
Enterprise Deployment Features:
- Advanced Update Strategies: Sophisticated rolling update configurations with progress tracking
- Multi-Container Patterns: Sidecar containers for metrics collection and logging
- Security Integration: Vault integration, service accounts, and comprehensive security contexts
- Observability: Integrated metrics, tracing, and structured logging
- Resource Governance: Comprehensive resource management with priority classes
- High Availability: Anti-affinity rules, topology spread constraints, and zone distribution
Enterprise Rolling Update Strategies
Enterprise deployments require sophisticated update strategies that ensure zero downtime while maintaining security and compliance requirements.
Advanced Rolling Update Configuration:
# Enterprise rolling update with comprehensive monitoring
kubectl set image deployment/enterprise-nginx-deployment nginx=registry.enterprise.com/nginx:1.22.0-alpine --record=true
# Monitor rollout with detailed status
kubectl rollout status deployment/enterprise-nginx-deployment --timeout=600s
# Verify deployment health across all zones
kubectl get pods -l app=nginx -o wide --show-labels
# Check metrics during rollout
kubectl top pods -l app=nginx
Enterprise Update Workflow:
Enterprise Rollback and History Management:
# View comprehensive rollout history with annotations
kubectl rollout history deployment/enterprise-nginx-deployment
# Get detailed revision information with change tracking
kubectl rollout history deployment/enterprise-nginx-deployment --revision=3
# Enterprise rollback with validation
kubectl rollout undo deployment/enterprise-nginx-deployment --to-revision=2
# Pause rollout for canary analysis
kubectl rollout pause deployment/enterprise-nginx-deployment
# Resume after validation
kubectl rollout resume deployment/enterprise-nginx-deployment
# Emergency rollback with immediate execution
kubectl rollout undo deployment/enterprise-nginx-deployment --to-revision=1 --force=true
Canary Deployment Pattern:
# Canary deployment configuration
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: enterprise-nginx-canary
spec:
replicas: 10
strategy:
canary:
canaryService: nginx-canary-service
stableService: nginx-stable-service
trafficRouting:
istio:
virtualService:
name: nginx-virtual-service
steps:
- setWeight: 10
- pause: {duration: 2m}
- setWeight: 20
- pause: {duration: 2m}
- analysis:
templates:
- templateName: success-rate
args:
- name: service-name
value: nginx-canary-service
- setWeight: 50
- pause: {duration: 5m}
- setWeight: 100
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: registry.enterprise.com/nginx:1.22.0-alpine
Enterprise StatefulSets and DaemonSets
Enterprise stateful workloads and system-level services require specialized orchestration patterns that address persistent storage, ordered operations, and node-level deployment requirements.

1. DaemonSets
DaemonSets ensure that all (or some) nodes run a copy of a Pod, making them ideal for node-level operations, monitoring, or services.
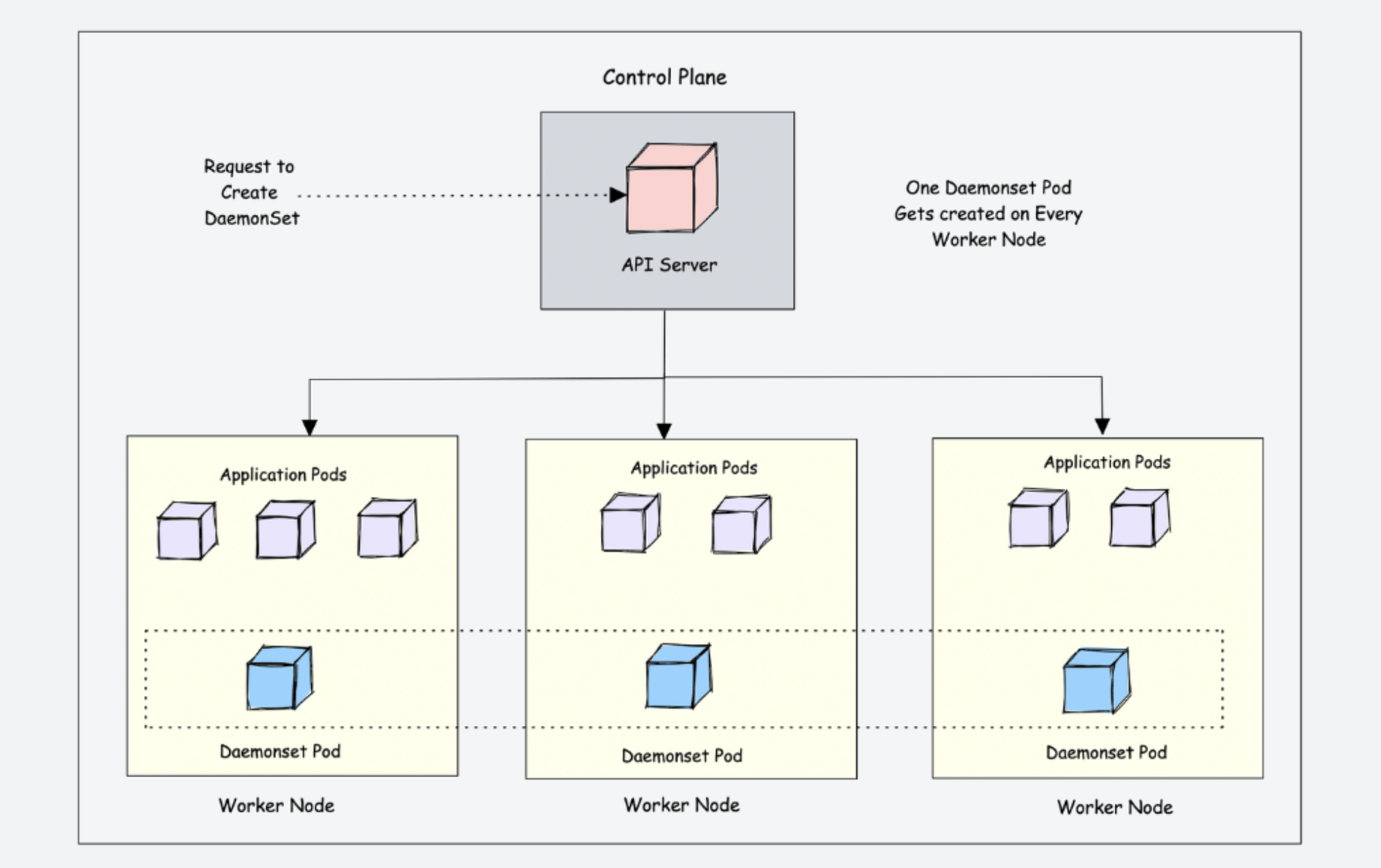
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd-elasticsearch
namespace: kube-system
spec:
selector:
matchLabels:
name: fluentd-elasticsearch
template:
metadata:
labels:
name: fluentd-elasticsearch
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: fluentd-elasticsearch
image: quay.io/fluentd_elasticsearch/fluentd:v2.5.2
resources:
limits:
memory: 200Mi
requests:
cpu: 100m
memory: 200Mi
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
hostPath:
path: /var/log
Key characteristics:
- Run exactly one Pod instance per node
- New Pods are automatically created when nodes are added to the cluster
- Pods are garbage-collected when nodes are removed
- Ideal for cluster-wide services like:
- Node monitoring agents
- Log collectors
- Network plugins
- Storage plugins
Example Use Cases:
- Prometheus Node Exporter
- Fluentd/Fluent Bit log collectors
- CNI network plugins (Calico, Cilium)
- Storage drivers
- Node-level security agents
DaemonSet Scheduling
DaemonSet Pods are scheduled using:
- NodeSelector
- NodeAffinity
- Tolerations to run on nodes with specific taints
- Priority classes to ensure critical system services run first
# View DaemonSets running on the cluster
kubectl get daemonset -n kube-system
# Examine a specific DaemonSet
kubectl describe daemonset calico-node -n kube-system
2. StatefulSets
StatefulSets are specialized workload resources designed for stateful applications requiring stable network identities and persistent storage.
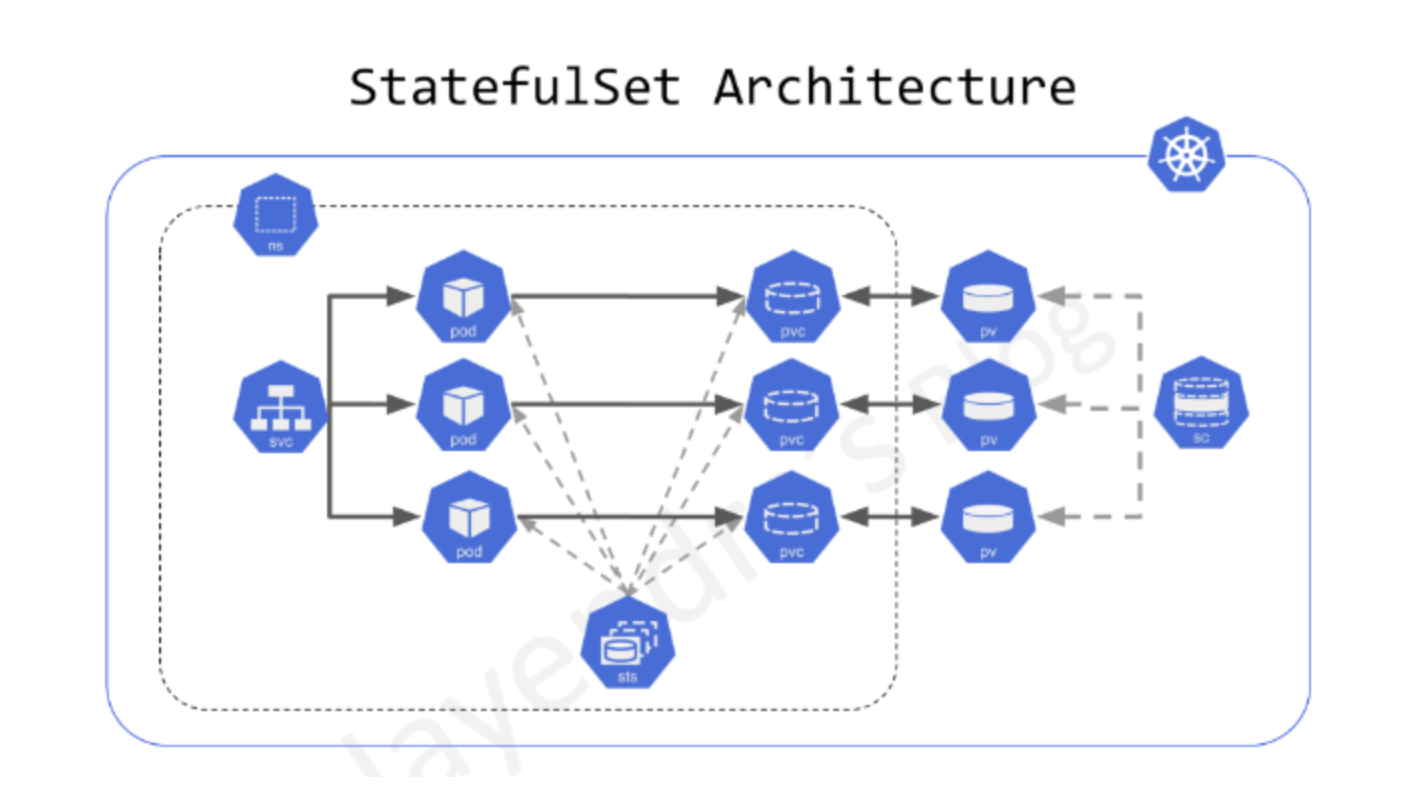
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: postgres
spec:
serviceName: "postgres"
replicas: 3
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:13
ports:
- containerPort: 5432
name: postgredb
env:
- name: POSTGRES_PASSWORD
valueFrom:
secretKeyRef:
name: postgres-secret
key: password
volumeMounts:
- name: postgres-data
mountPath: /var/lib/postgresql/data
volumeClaimTemplates:
- metadata:
name: postgres-data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 10Gi
Key characteristics:
- Provide stable, unique network identities (e.g., postgres-0, postgres-1, postgres-2)
- Create PersistentVolumes for each Pod using volumeClaimTemplates
- Ordered, graceful deployment and scaling
- Ordered, graceful deletion and termination
- Maintain sticky identity even after rescheduling
- Guarantee startup/shutdown order
- Support headless services for direct Pod access
Example Use Cases:
- Databases (MySQL, PostgreSQL, MongoDB)
- Distributed systems (Elasticsearch, Kafka, RabbitMQ)
- Any application requiring persistent identity/storage
- Applications where ordering matters (leader-follower patterns)
StatefulSet Update Strategies
- RollingUpdate: Update Pods in reverse ordinal order
- OnDelete: Update only when Pods are manually deleted
- Partition: Only update Pods with an ordinal greater than or equal to the partition value
# Scale a StatefulSet
kubectl scale statefulset postgres --replicas=5
# Get Persistent Volume Claims created by a StatefulSet
kubectl get pvc -l app=postgres
Jobs and CronJobs
These resource types manage task execution and scheduling within the cluster.
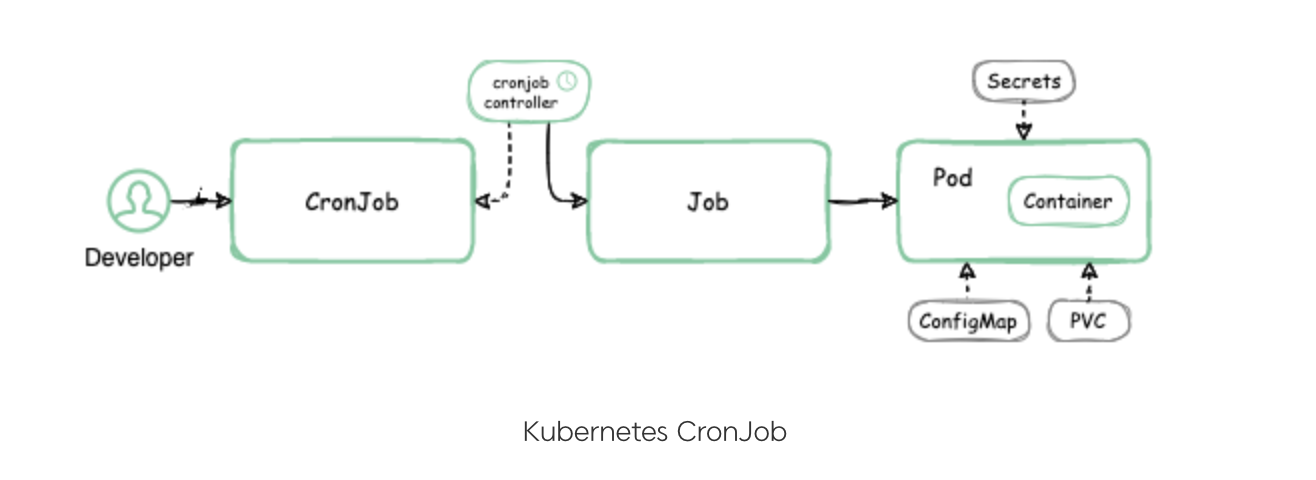
1. Jobs
Jobs create one or more Pods and ensure that a specified number of them successfully terminate.
apiVersion: batch/v1
kind: Job
metadata:
name: data-processor
spec:
parallelism: 3
completions: 5
backoffLimit: 2
activeDeadlineSeconds: 300
template:
spec:
containers:
- name: data-processor
image: my-data-processor:v1
command: ["python", "process_data.py"]
resources:
requests:
memory: "128Mi"
cpu: "100m"
limits:
memory: "256Mi"
cpu: "200m"
restartPolicy: OnFailure
Key characteristics:
- Run to completion rather than running indefinitely
- Track successful completions
- Can run multiple Pods in parallel
- Can specify how many successful completions are needed
- Handle backoff for failures (automatic retries)
- Can set timeouts for job execution
Job Execution Patterns:
- Single Job (Non-parallel): One Pod running to completion
- Fixed Completion Count: Multiple Pods running sequentially until reaching a completion count
- Parallel Jobs with Fixed Completion Count: Multiple Pods running in parallel until reaching a completion count
- Parallel Jobs with Work Queue: Multiple Pods processing items from a shared work queue
Example Use Cases:
- Database migrations
- Batch data processing
- File conversion tasks
- Periodic calculations
- Backup operations
- ETL workflows
2. CronJobs
CronJobs create Jobs on a time-based schedule, executing recurring tasks at specified intervals.
apiVersion: batch/v1
kind: CronJob
metadata:
name: database-backup
spec:
schedule: "0 2 * * *"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1
startingDeadlineSeconds: 120
jobTemplate:
spec:
template:
spec:
containers:
- name: backup
image: my-db-backup:v1
command:
- /bin/sh
- -c
- echo "Starting backup"; sleep 5; echo "Backup completed"
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-creds
key: password
restartPolicy: OnFailure
Key characteristics:
- Schedule using standard cron format (
* * * * *) - Create Jobs automatically according to schedule
- Manage concurrency with policies
- Handle job execution deadlines
- Maintain job history
- Support time zones
CronJob Schedule Format:
# ┌───────────── minute (0 - 59)
# │ ┌───────────── hour (0 - 23)
# │ │ ┌───────────── day of the month (1 - 31)
# │ │ │ ┌───────────── month (1 - 12)
# │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday)
# │ │ │ │ │
# * * * * *
Concurrency Policies:
- Allow: Allow concurrently running jobs (default)
- Forbid: Skip the next run if previous hasn’t finished
- Replace: Cancel the currently running job and start a new one
Example Use Cases:
- Scheduled backups
- Report generation
- Cleanup tasks
- Data synchronization
- Health checks
- Periodic data processing
# Check CronJob status
kubectl get cronjobs
# View the next scheduled run time
kubectl get cronjob database-backup -o json | jq '.status.lastScheduleTime'
# Manually trigger a CronJob
kubectl create job --from=cronjob/database-backup backup-manual-trigger
Resource Comparison and Selection Guide
Choosing the Right Resource Type
Selecting the appropriate Kubernetes resource is crucial for your application's reliability, scalability, and maintainability.
Consider your application's state requirements, scaling patterns, update strategies, and operational needs.
| Feature | Deployment | StatefulSet | DaemonSet | Job/CronJob |
|---|---|---|---|---|
| Primary Use Case | Stateless applications | Stateful applications | Node-level operations | Batch/scheduled tasks |
| Scaling | Dynamic/Horizontal | Ordered, sequential | One per node | Parallelism control |
| Pod Identity | Ephemeral, random | Stable, predictable | Node-based | Ephemeral, random |
| Storage | Usually ephemeral | Persistent per Pod | Optional | Usually ephemeral |
| Update Strategy | Rolling update | Ordered, controlled | Rolling update | Recreate |
| Pod Termination | Any order | Ordered (high to low index) | Based on node removal | After completion |
| Network Identity | Service (load-balanced) | Headless service with DNS | Host network or standard | Optional |
| Example Workloads | Web servers, API services | Databases, message queues | Monitoring, logging agents | Batch processing, backups |
| Self-healing | Yes | Yes (maintains identity) | Yes (maintains node coverage) | Optional (with restartPolicy) |
Decision Flowchart
Best Practices
- Define resource requests and limits to ensure proper scheduling and prevent resource contention
- Use labels and annotations for better organization and integration with other tools
- Set appropriate liveness and readiness probes to enhance reliability
- Configure Pod Disruption Budgets (PDBs) for critical workloads
- Use namespaces to organize and isolate resources
Resource-Specific Recommendations
- Deployments: Use the RollingUpdate strategy with appropriate maxSurge and maxUnavailable values
- StatefulSets: Always use a headless service and configure proper volumeClaimTemplates
- DaemonSets: Use tolerations to run on tainted nodes when necessary
- Jobs: Set appropriate backoffLimit and activeDeadlineSeconds to handle failures
- CronJobs: Choose the right concurrencyPolicy and set history limits to manage resource consumption
References
- Kubernetes Official Documentation - Workloads
- Kubernetes Official Documentation - Deployments
- Kubernetes Official Documentation - StatefulSets
- Kubernetes Official Documentation - DaemonSets
- Kubernetes Official Documentation - Jobs
- Kubernetes Official Documentation - CronJobs
- StatefulSets Guide
- DaemonSet Tutorial

Comments