11 min to read
Safe Pod Termination in Kubernetes - A Complete Guide
Mastering cordon, uncordon, drain, and scale commands for reliable cluster maintenance
Overview
Managing Pod termination safely is crucial in Kubernetes operations, especially during maintenance, updates, or scaling activities. Proper termination procedures ensure application stability, data integrity, and minimal service disruption.
When containers are terminated in Kubernetes, they receive a SIGTERM signal, allowing them to shut down gracefully. If the application doesn’t terminate within the grace period (default 30 seconds), a SIGKILL signal forcibly terminates the container. Understanding and implementing proper termination handling is essential for robust Kubernetes workloads.
Why Pod Termination Matters
Improper pod termination can lead to data corruption, transaction loss, incomplete processing, and customer-facing downtime. Well-managed termination processes ensure:
- Graceful completion of in-flight requests
- Proper database connection closure
- State persistence where needed
- Minimal user impact during maintenance
Pod Termination Commands and Concepts
Pod Management Commands
In Kubernetes, Pod termination can be handled in several ways depending on your operational requirements:
| Command | Description | Example |
|---|---|---|
cordon |
Marks a node as unschedulable, preventing new pods from being scheduled | kubectl cordon node-1 |
uncordon |
Marks a node as schedulable, allowing new pods to be scheduled | kubectl uncordon node-1 |
drain |
Safely evicts all pods from a node and marks it as unschedulable | kubectl drain node-1 --ignore-daemonsets --delete-local-data |
scale |
Adjusts the number of replicas in a Deployment, ReplicaSet, or StatefulSet | kubectl scale --replicas=0 deployment/frontend |
Important Command Flags
# Drain command options
kubectl drain <node-name> [options]
# Common options:
--ignore-daemonsets # Ignore DaemonSet-managed pods
--delete-local-data # Delete pods with local storage
--force # Continue even if there are unmanaged pods
--grace-period=<seconds> # Period of time given to each pod to terminate gracefully
--timeout=<duration> # Maximum time to wait before giving up (e.g., 5m)
Pod Lifecycle During Termination
StatefulSet vs Stateless Applications
Managing termination differs significantly between stateful and stateless applications:
Stateless Applications
Stateless applications don’t maintain client session data between requests, making them simpler to scale and terminate:
# Directly scale down a stateless deployment to zero
kubectl scale --replicas=0 deployment/frontend -n <namespace>
Key considerations:
- No specific shutdown sequence required
- Can be terminated in any order
- Load balancers should stop sending traffic before termination
- In-flight requests should be allowed to complete
StatefulSet Applications
StatefulSet-based applications often maintain state and may require orderly shutdown:
# Sequential scaling for StatefulSets (e.g., database cluster)
kubectl scale --replicas=2 statefulset/db-cluster -n <namespace>
# Wait for stable state
kubectl scale --replicas=1 statefulset/db-cluster -n <namespace>
# Wait for stable state
kubectl scale --replicas=0 statefulset/db-cluster -n <namespace>
Key considerations:
- Specific shutdown order may be critical
- Data replication should complete before termination
- Leader election or primary/secondary roles may need handling
- Consider using PreStop hooks for clean shutdown procedures
Pod Disruption Budget (PDB)
A Pod Disruption Budget (PDB) is a Kubernetes resource that limits the number of pods of a replicated application that can be down simultaneously from voluntary disruptions.
PDB Example
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: app-pdb
spec:
minAvailable: 2 # OR
# maxUnavailable: 1
selector:
matchLabels:
app: critical-service
You can specify either minAvailable or maxUnavailable in a PDB, but not both:
- minAvailable: Ensures at least N pods are always available
- maxUnavailable: Ensures no more than N pods are unavailable
Values can be absolute numbers or percentages (e.g., "50%").
PDB Behavior During Operations
| Operation | PDB Impact |
|---|---|
| Node Drain | If evicting a pod would violate PDB, the drain operation will wait until pods are rescheduled |
| Manual Deletion | PDB doesn't prevent manual pod deletion, only voluntary disruptions like drains |
| Cluster Autoscaling | Respects PDBs when deciding which nodes to remove |
| Rolling Updates | Deployment controller respects PDBs during rolling updates |
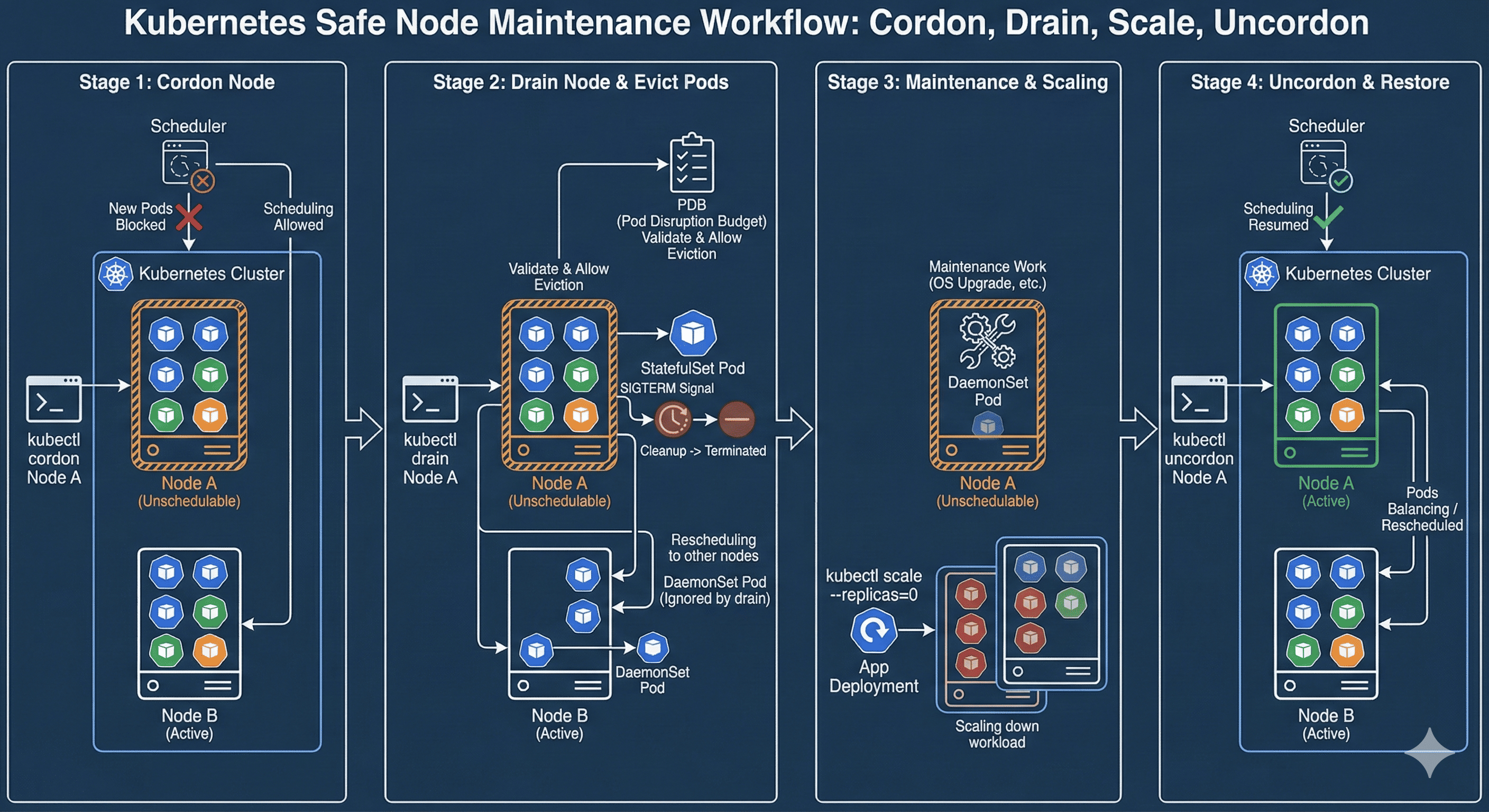
Node Management Workflow
The typical node maintenance workflow involves three key operations: cordon, drain, and uncordon.
Detailed Procedure
# 1. Mark the node as unschedulable
kubectl cordon node-1
# 2. Check if node is marked as unschedulable
kubectl get nodes
# 3. Drain the node (evict pods)
kubectl drain node-1 --ignore-daemonsets --delete-local-data
# 4. Perform maintenance tasks on the node
# ... (OS updates, kernel patches, hardware changes, etc.)
# 5. Make the node schedulable again
kubectl uncordon node-1
# 6. Verify node status
kubectl get nodes
- Plan maintenance windows during low-traffic periods
- Ensure capacity - have enough resources to handle redistributed workloads
- Monitor PDB compliance before initiating maintenance
- Perform maintenance in batches for multi-node clusters
- Verify application health after each node returns to service
- Have rollback plans for failed maintenance operations
Command Comparison and Use Cases
| Command | Use Cases | Advantages | Limitations |
|---|---|---|---|
cordon |
- Preparing for maintenance - Isolating problematic nodes - Staged decommissioning |
- Minimal impact - No pod disruption - Quick operation |
- Doesn't relocate existing pods - Manual follow-up required |
drain |
- Node maintenance/updates - Decommissioning nodes - Cluster resizing |
- Automated pod eviction - Respects PDBs - Safe workload migration |
- Can be blocked by PDBs - May disrupt stateful workloads - Takes more time |
uncordon |
- After maintenance completion - Re-enabling nodes - Scaling up capacity |
- Quick operation - Allows workload rebalancing - No direct pod disruption |
- Doesn't trigger immediate pod scheduling - May need manual rebalancing |
scale |
- Application updates - Cost optimization - Traffic management |
- Targeted to specific workloads - Highly controllable - Application-specific |
- Doesn't affect node scheduling - Requires workload-specific knowledge |
Graceful Shutdown Implementation
PreStop Hook Configuration
The preStop hook allows you to run commands before a container receives the SIGTERM signal:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-app
spec:
template:
spec:
containers:
- name: web-app
image: my-web-app:1.0
lifecycle:
preStop:
exec:
command: ["/bin/sh", "-c", "sleep 10 && /app/cleanup.sh"]
Termination Grace Period
You can customize how long Kubernetes waits before forcibly terminating a pod:
apiVersion: apps/v1
kind: Deployment
metadata:
name: database
spec:
template:
spec:
terminationGracePeriodSeconds: 60 # Default is 30 seconds
containers:
- name: database
image: mysql:8.0
Application-Level Handling
Your application should handle SIGTERM signals properly:
# Python example of SIGTERM handling
import signal
import sys
import time
def graceful_shutdown(signum, frame):
print("Received shutdown signal, cleaning up...")
# Close database connections
# Finish processing current requests
# Save state if needed
time.sleep(5) # Simulate cleanup work
print("Cleanup complete, exiting")
sys.exit(0)
signal.signal(signal.SIGTERM, graceful_shutdown)
# Main application code...
while True:
# Application logic
time.sleep(1)
Advanced Scenarios
Rolling Node Updates in Production
For larger clusters with critical workloads, consider a staggered approach:
# Script example for rolling node maintenance
#!/bin/bash
NODES=$(kubectl get nodes -l role=worker -o name | cut -d/ -f2)
for NODE in $NODES; do
echo "Processing node $NODE"
# Check node status and PDB compliance first
kubectl cordon "$NODE"
echo "Waiting for node to drain..."
if kubectl drain "$NODE" --ignore-daemonsets --delete-local-data --timeout=5m; then
echo "Node $NODE drained successfully"
echo "Perform maintenance now, then press Enter to continue"
read
kubectl uncordon "$NODE"
echo "Node $NODE is back in service"
# Wait for workloads to stabilize before moving to next node
echo "Waiting 5 minutes for workloads to stabilize"
sleep 300
else
echo "Failed to drain node $NODE, skipping"
kubectl uncordon "$NODE"
fi
done
Handling Stuck Pod Termination
Sometimes pods may get stuck in Terminating state:
# Check for stuck pods
kubectl get pods | grep Terminating
# Force delete a stuck pod
kubectl delete pod stuck-pod --grace-period=0 --force
Force deleting pods can lead to resource leaks or data corruption. Only use this as a last resort and be prepared to clean up orphaned resources.
Monitoring Pod Termination
Commands for Observing Pod Status
# Watch pods during termination process
kubectl get pods -w
# Check pod detailed status
kubectl describe pod <pod-name>
# Check pod termination logs
kubectl logs <pod-name> --previous
# Monitor events during termination
kubectl get events --sort-by='.lastTimestamp'
Using Metrics and Logs
Consider implementing:
- Prometheus metrics for tracking termination duration
- Grafana dashboards for visualizing pod lifecycle events
- Application logs with shutdown sequences clearly marked
- Event monitoring to catch termination-related issues
Key Points
-
Before Termination
- Verify PDB compliance
- Ensure sufficient cluster capacity
- Plan for stateful application handling -
During Termination
- Monitor eviction process
- Check for stuck terminating pods
- Observe application behavior -
After Termination
- Verify replacement pods
- Check service availability
- Confirm application functionality

Comments