18 min to read
Kubernetes Operators and Custom Resource Definitions (CRDs)
Extending Kubernetes with domain-specific automation and custom APIs
Overview
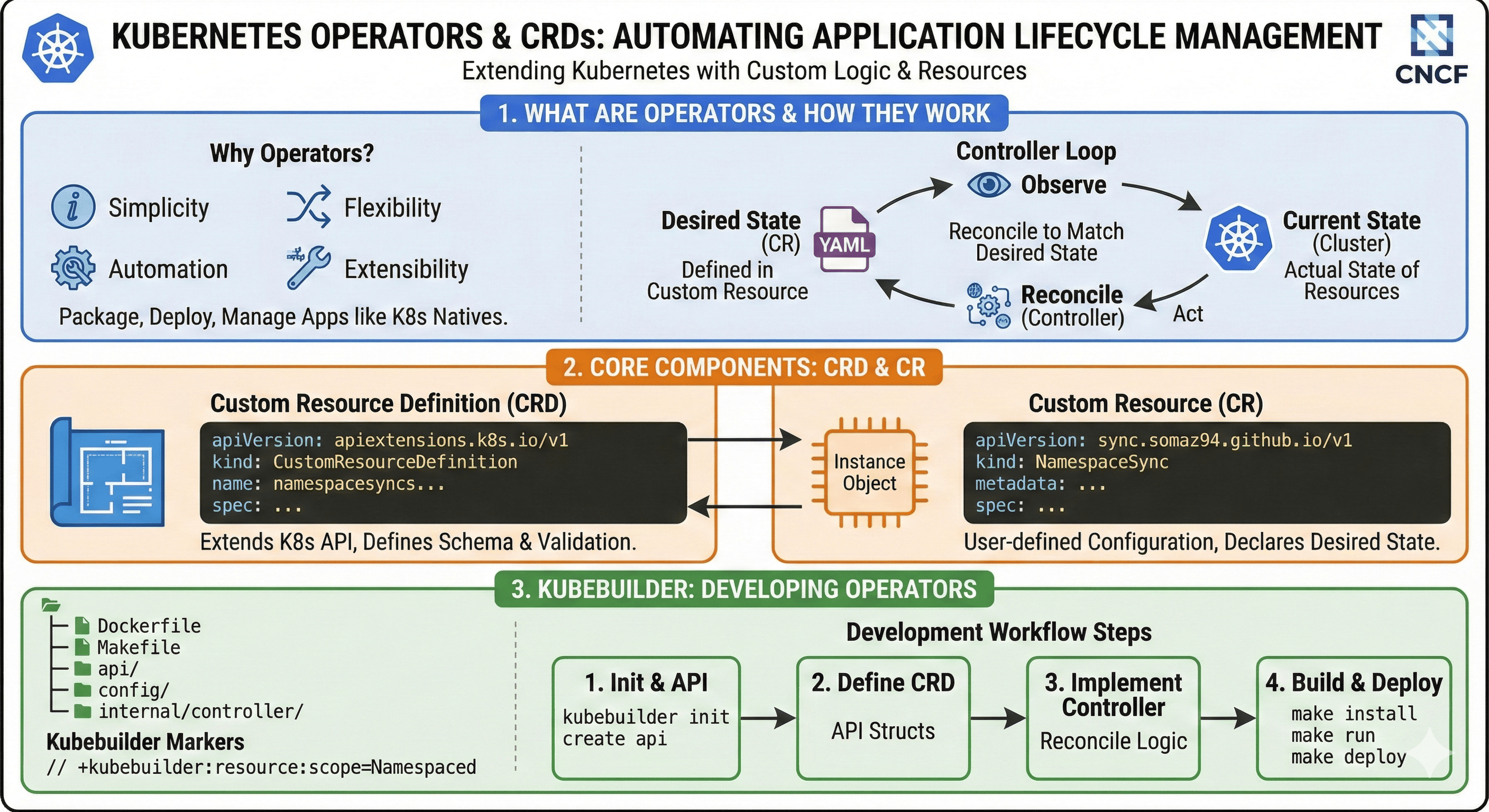
Kubernetes Operators and Custom Resource Definitions (CRDs) are powerful mechanisms for extending Kubernetes functionality beyond its built-in capabilities. This guide covers what they are, how they work together, and how to develop your own extensions to Kubernetes.
At its core, Kubernetes operates on a simple principle: define the desired state of your system, and controllers will work to maintain that state. Operators extend this paradigm to complex, application-specific operations by encoding operational knowledge into software.
Kubernetes Operators: Automation for Complex Applications
What is an Operator?
An Operator is a Kubernetes-native application that watches and takes action on specific resources, implementing domain-specific operational knowledge in code.
Operator Components:
- Custom Resource Definition (CRD):
- Defines a new resource type in the Kubernetes API
- Describes the schema and validation rules
- Controller:
- Implements the control loop logic
- Watches for changes to custom resources
- Takes actions to reconcile actual state with desired state
- Domain-specific Knowledge:
- Encoded operational expertise
- Application lifecycle management rules
- Complex operational procedures automated in code
The concept of Operators was introduced by CoreOS (now part of Red Hat) in 2016. They were designed to solve the challenge of managing stateful applications in Kubernetes, which require domain-specific knowledge for operations like scaling, upgrading, and backup/restore.
The name "Operator" comes from the human operators who traditionally managed such complex applications manually.
The Operator Pattern
Operators follow the Kubernetes reconciliation pattern:
- Observe: Monitor the state of the custom resource
- Analyze: Compare current state with desired state
- Act: Execute changes to reach the desired state
- Update: Record the current state in the resource’s status
Why Use Operators?
- Automation: Codify complex operational tasks to reduce manual intervention
- Consistency: Ensure identical operations across environments
- Reliability: Reduce human error through tested, automated procedures
- Domain-specific: Encode specialized knowledge for specific applications
- Kubernetes-native: Integrate with existing Kubernetes tools and workflows
Real-world Applications
Operators are particularly valuable for managing:
| Application Type | Operational Challenges | Example Operators |
|---|---|---|
| Databases |
- Replication configuration - Scaling with data integrity - Backup and restore - Version upgrades |
- PostgreSQL Operator - MongoDB Community Operator - Redis Operator - Cassandra Operator |
| Message Queues |
- Cluster configuration - Topic management - Network partitioning |
- Kafka Operator - RabbitMQ Operator |
| Infrastructure |
- Certificate management - Network policy enforcement - Monitoring configuration |
- cert-manager - Prometheus Operator - Istio Operator |
Operator Maturity Model
Operators range in sophistication according to the Red Hat Operator Maturity Model:
- Level 1 - Basic Install: Automated application installation and configuration
- Level 2 - Seamless Upgrades: Patch and minor version upgrades
- Level 3 - Full Lifecycle: Application backups, failure recovery
- Level 4 - Deep Insights: Application metrics, alerts, optimized configurations based on usage
- Level 5 - Auto Pilot: Automatic scaling, auto-tuning, anomaly detection and resolution
Custom Resource Definitions (CRDs): Extending the Kubernetes API
What are CRDs?
CRDs allow you to define new resource types that extend the Kubernetes API, making custom resources feel like native Kubernetes objects.
Custom resources work just like native Kubernetes resources:
- Accessed through the same API endpoints
- Managed with kubectl and other Kubernetes clients
- Secured through RBAC and admission controls
- Stored in etcd alongside built-in resources
- Watched for changes through the same mechanisms
CRD Architecture
CRD Components
1. The CRD Itself
Defines the schema, validation, and naming for your custom resource type:
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: databases.example.com
spec:
group: example.com
names:
kind: Database
plural: databases
singular: database
shortNames:
- db
scope: Namespaced
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
required: ["spec"]
properties:
spec:
type: object
required: ["engine", "version"]
properties:
engine:
type: string
enum: ["postgres", "mysql", "mongodb"]
version:
type: string
replicas:
type: integer
minimum: 1
default: 1
storage:
type: string
pattern: "^\\d+Gi$"
status:
type: object
properties:
phase:
type: string
readyReplicas:
type: integer
subresources:
status: {}
additionalPrinterColumns:
- name: Engine
type: string
jsonPath: .spec.engine
- name: Version
type: string
jsonPath: .spec.version
- name: Replicas
type: integer
jsonPath: .spec.replicas
- name: Status
type: string
jsonPath: .status.phase
2. Custom Resources
Instances of your custom type that users create:
apiVersion: example.com/v1
kind: Database
metadata:
name: my-production-db
spec:
engine: postgres
version: "13.4"
replicas: 3
storage: "20Gi"
3. Controller/Operator
Software that watches for custom resources and takes actions to align the actual state with the desired state.
Advanced CRD Features
Schema Validation
The schema section of a CRD defines the structure and validation rules for your custom resource:
- Required fields: Enforce mandatory configuration
- Field types: Validate data types (string, integer, boolean, object, array)
- Enumerations: Restrict values to a predefined set
- Patterns: Validate format using regular expressions
- Ranges: Set minimum and maximum values for numbers
- Defaults: Provide default values when not specified
Additional Printer Columns
Define custom columns for kubectl get output:
$ kubectl get databases
NAME ENGINE VERSION REPLICAS STATUS
my-production-db postgres 13.4 3 Running
dev-database mysql 8.0 1 Provisioning
Subresources
Subresources provide special endpoints for custom resources:
- Status: Separate the “spec” (desired state) from “status” (actual state)
- Scale: Enable scaling operations via the scale subresource
Building Operators: Tools and Frameworks
Multiple frameworks exist to simplify operator development:
| Framework | Description | Best For |
|---|---|---|
| Kubebuilder |
- Developed by Kubernetes SIG API Machinery - Uses Go programming language - Includes scaffolding, testing tools, and libraries |
- Complex operators - Large-scale projects - Deep integration |
| Operator SDK |
- Part of the Operator Framework by Red Hat - Supports Go, Ansible, and Helm - Includes Operator Lifecycle Manager integration |
- Multi-language support - Quick prototyping - OLM deployment |
| KUDO |
- CNCF sandbox project - Declarative approach - Operator building for non-programmers |
- Simple operators - Non-developers - Quick adoption |
| Kopf |
- Python-based framework - Lightweight design - Focus on simplicity |
- Python developers - Rapid prototyping - Smaller projects |
Deep Dive: Kubebuilder Framework
Kubebuilder is a popular framework for building Kubernetes APIs and controllers using Go.
Project Structure
.
├── Dockerfile # Container image definition
├── Makefile # Build, test, deploy commands
├── PROJECT # Project metadata
├── api/ # CRD API definitions
│ └── v1/
│ ├── database_types.go # Custom resource type definition
│ ├── groupversion_info.go
│ └── zz_generated.deepcopy.go
├── config/ # Kubernetes manifests
│ ├── crd/ # Generated CRD YAML
│ ├── rbac/ # Role-based access control
│ ├── manager/ # Controller manager deployment
│ └── samples/ # Example custom resources
├── controllers/ # Controller implementation
│ ├── database_controller.go
│ └── suite_test.go
└── main.go # Entry point
Core Components in Code
1. API Type Definition:
// Database is the Schema for the databases API
type Database struct {
metav1.TypeMeta `json:",inline"`
metav1.ObjectMeta `json:"metadata,omitempty"`
Spec DatabaseSpec `json:"spec,omitempty"`
Status DatabaseStatus `json:"status,omitempty"`
}
// DatabaseSpec defines the desired state of Database
type DatabaseSpec struct {
Engine string `json:"engine"`
Version string `json:"version"`
Replicas int `json:"replicas,omitempty"`
Storage string `json:"storage,omitempty"`
}
// DatabaseStatus defines the observed state of Database
type DatabaseStatus struct {
Phase string `json:"phase,omitempty"`
ReadyReplicas int `json:"readyReplicas,omitempty"`
}
2. Controller Implementation:
// DatabaseReconciler reconciles a Database object
type DatabaseReconciler struct {
client.Client
Log logr.Logger
Scheme *runtime.Scheme
}
// +kubebuilder:rbac:groups=example.com,resources=databases,verbs=get;list;watch;create;update;patch;delete
// +kubebuilder:rbac:groups=example.com,resources=databases/status,verbs=get;update;patch
func (r *DatabaseReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
log := r.Log.WithValues("database", req.NamespacedName)
// Fetch the Database instance
var database examplecomv1.Database
if err := r.Get(ctx, req.NamespacedName, &database); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// Your reconciliation logic here
// 1. Check if StatefulSet exists, create if not
// 2. Ensure StatefulSet matches desired state
// 3. Update status with current state
return ctrl.Result{}, nil
}
3. Main Function:
func main() {
// Setup manager, scheme, controllers
mgr, err := ctrl.NewManager(ctrl.GetConfigOrDie(), ctrl.Options{
Scheme: scheme,
MetricsBindAddress: metricsAddr,
Port: 9443,
LeaderElection: enableLeaderElection,
})
if err != nil {
setupLog.Error(err, "unable to start manager")
os.Exit(1)
}
// Register controller
if err = (&controllers.DatabaseReconciler{
Client: mgr.GetClient(),
Log: ctrl.Log.WithName("controllers").WithName("Database"),
Scheme: mgr.GetScheme(),
}).SetupWithManager(mgr); err != nil {
setupLog.Error(err, "unable to create controller", "controller", "Database")
os.Exit(1)
}
// Start manager
setupLog.Info("starting manager")
if err := mgr.Start(ctrl.SetupSignalHandler()); err != nil {
setupLog.Error(err, "problem running manager")
os.Exit(1)
}
}
Common Development Commands
# Initialize new project
kubebuilder init --domain example.com
# Create API (generates CRD and controller)
kubebuilder create api --group example --version v1 --kind Database
# Generate manifests
make manifests
# Install CRDs
make install
# Run controller locally (development)
make run
# Build and push container image
make docker-build docker-push IMG=example.com/operator:v0.1.0
# Deploy to cluster
make deploy IMG=example.com/operator:v0.1.0
Development Workflow
Stages of Operator Development
| Stage | Activities | Best Practices |
|---|---|---|
| Design |
- Define CRD specs - Plan controller logic - Design API schema |
- Keep schema simple and focused - Define clear validation rules - Consider versioning strategy early - Document field purposes and constraints |
| Implementation |
- Write controller code - Implement reconciliation - Add validation |
- Follow idempotent design patterns - Use owner references for created resources - Handle edge cases and error conditions - Leverage finalizers for cleanup logic |
| Testing |
- Unit tests - Integration tests - E2E testing |
- Mock external dependencies - Test scenarios for error handling - Use envtest for controller tests - Create test fixtures for common scenarios |
| Deployment |
- Build container image - Deploy to cluster - Monitor performance |
- Use minimal base images - Set resource requests/limits - Configure proper RBAC permissions - Implement health checks and metrics |
Best Practices
- Follow Kubernetes conventions for naming, structure, and versioning
- Use semantic versioning for your API versions
- Make fields optional when possible to improve forward compatibility
- Set defaults for optional fields to simplify usage
- Use strong validation to catch misconfigurations early
- Document all fields with clear descriptions
- Design for idempotency - controllers should safely retry operations
- Handle errors gracefully with appropriate retries and backoffs
- Implement informative logging for debugging and auditing
- Update status frequently to reflect the current state
- Add finalizers for proper cleanup on deletion
- Set owner references for automatic cleanup of dependent resources
- Write comprehensive tests for controller logic
- Test edge cases and recovery scenarios
- Implement leader election for high availability
- Export metrics for performance monitoring
- Add thorough documentation for users of your operator
Real-world Example: Simple Namespace Synchronization Operator
This example demonstrates a basic operator that synchronizes configurations across namespaces.
CRD Definition
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
name: namespacesynchronizations.sync.example.com
spec:
group: sync.example.com
versions:
- name: v1
served: true
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
sourceNamespace:
type: string
targetNamespaces:
type: array
items:
type: string
resources:
type: array
items:
type: object
properties:
kind:
type: string
name:
type: string
status:
type: object
properties:
conditions:
type: array
items:
type: object
properties:
type:
type: string
status:
type: string
lastTransitionTime:
type: string
reason:
type: string
message:
type: string
scope: Cluster
names:
plural: namespacesynchronizations
singular: namespacesynchronization
kind: NamespaceSynchronization
shortNames:
- nssync
Custom Resource Example
apiVersion: sync.example.com/v1
kind: NamespaceSynchronization
metadata:
name: config-sync
spec:
sourceNamespace: base-config
targetNamespaces:
- team-a
- team-b
- team-c
resources:
- kind: ConfigMap
name: shared-config
- kind: Secret
name: common-credentials
Controller Logic Overview
The controller would:
- Watch for NamespaceSynchronization resources
- List the specified resources in the source namespace
- For each target namespace:
- Create or update the resources
- Handle differences in metadata (e.g., namespace)
- Apply owner references for tracking
- Update the status with sync results

Comments