16 min to read
What is BigQuery & Data Warehouse?
A comprehensive guide to BigQuery and Data Warehousing
Overview
In today’s data-driven world, organizations need powerful tools to store, process, and analyze massive volumes of data efficiently. Google BigQuery stands out as a leading solution in this space, offering a fully managed, serverless data warehouse that enables businesses to unlock insights from their data without managing complex infrastructure.
This comprehensive guide explores BigQuery’s architecture, features, and how it fits into the broader concept of data warehousing. We’ll also cover practical examples, best practices, and real-world applications to help you understand how BigQuery can transform your data analytics capabilities.
BigQuery emerged from Google's internal data processing tool called Dremel, which was designed to run interactive queries against massive datasets. Google published a research paper about Dremel in 2010, and later that year announced BigQuery as a public service.
The service became generally available in 2012 and has since evolved to become one of the most powerful cloud data warehouses in the market. BigQuery was built on the same technology that powers many of Google's own services like Search, Gmail, and YouTube, which process petabytes of data daily.
This heritage gives BigQuery unique capabilities in terms of scalability and performance that differentiate it from traditional data warehouse solutions that were designed for on-premises environments and later adapted to the cloud.
What is BigQuery?
BigQuery is Google’s fully managed, serverless data warehouse that enables super-fast SQL queries using the processing power of Google’s infrastructure. It allows you to analyze large datasets without having to manage any infrastructure or database administration tasks.
Key Characteristics of BigQuery
| Feature | Description | Benefit |
|---|---|---|
| Serverless Architecture | No provisioning or management of infrastructure required | Focus on analytics, not infrastructure |
| Columnar Storage | Data stored in optimized columnar format | Significantly faster analytics queries |
| Petabyte Scale | Handles datasets from GBs to PBs with the same performance | Scalability without performance degradation |
| Separation of Storage and Compute | Independent scaling of storage and query processing | Cost optimization and performance flexibility |
| SQL Support | ANSI-compliant SQL with extensions | Familiar query language with powerful features |
| Automatic High Availability | Redundant infrastructure with global replication options | 99.99% availability with no user management |
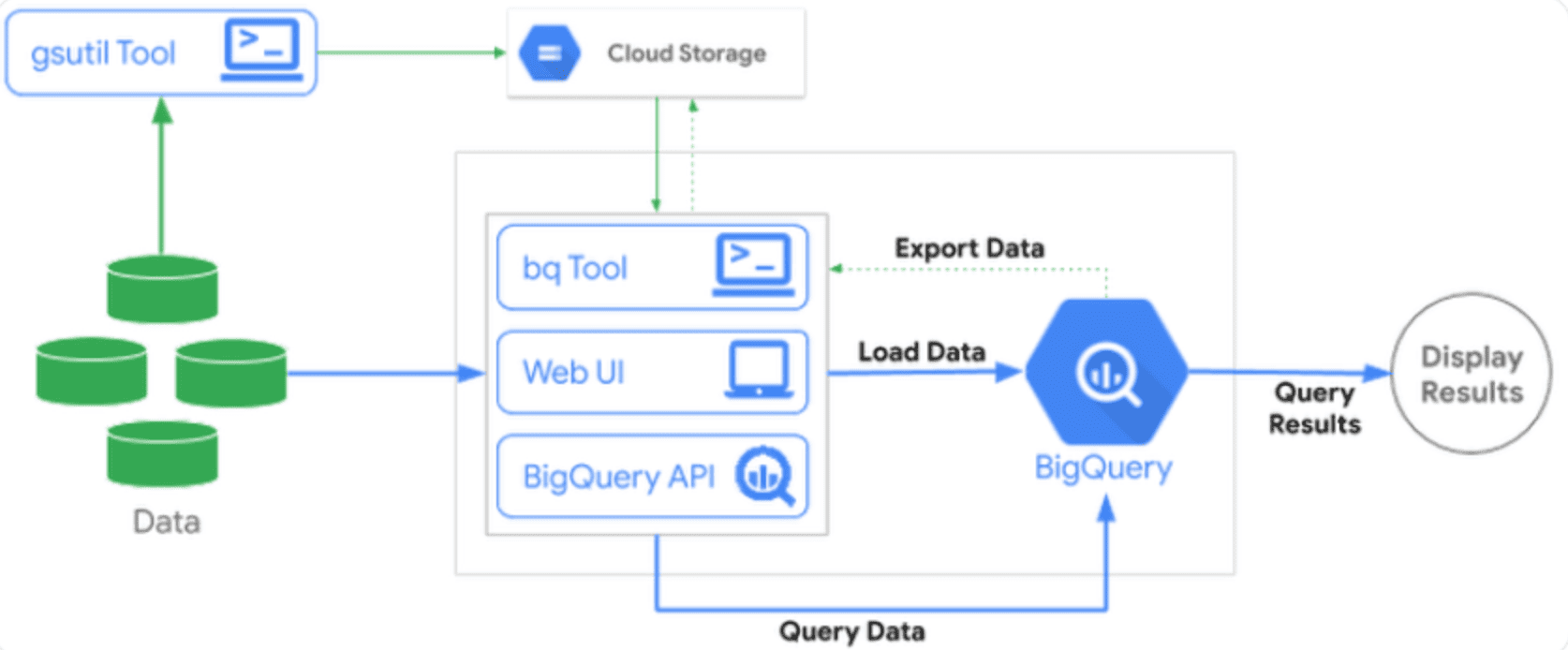
BigQuery Architecture
BigQuery’s architecture consists of four main components:
- Storage Layer: Columnar storage system optimized for analytical queries
- Compute Layer: Massively parallel processing (MPP) query execution engine
- Ingestion Services: Various methods to load and stream data
- Resource Management: Dynamic allocation of compute resources
This architecture enables BigQuery to scale horizontally, processing petabytes of data across thousands of servers in seconds.
What is a Data Warehouse?
A data warehouse is a central repository of integrated data from multiple sources, designed to support business intelligence activities, particularly analytics.
Unlike operational databases that support day-to-day transactions, data warehouses are optimized for query and analysis.
Key Characteristics of Data Warehouses
| Feature | Operational Database | Data Warehouse |
|---|---|---|
| Primary Purpose | Transaction processing (OLTP) | Analytics & reporting (OLAP) |
| Data Model | Normalized for data integrity | Denormalized for query performance |
| Query Patterns | Simple queries accessing few records | Complex queries scanning millions of records |
| Update Pattern | Frequent small transactions | Bulk periodic loads |
| Optimization | For write operations | For read operations |
| Schema | Rigid schema | Flexible schema (especially in modern DWs) |
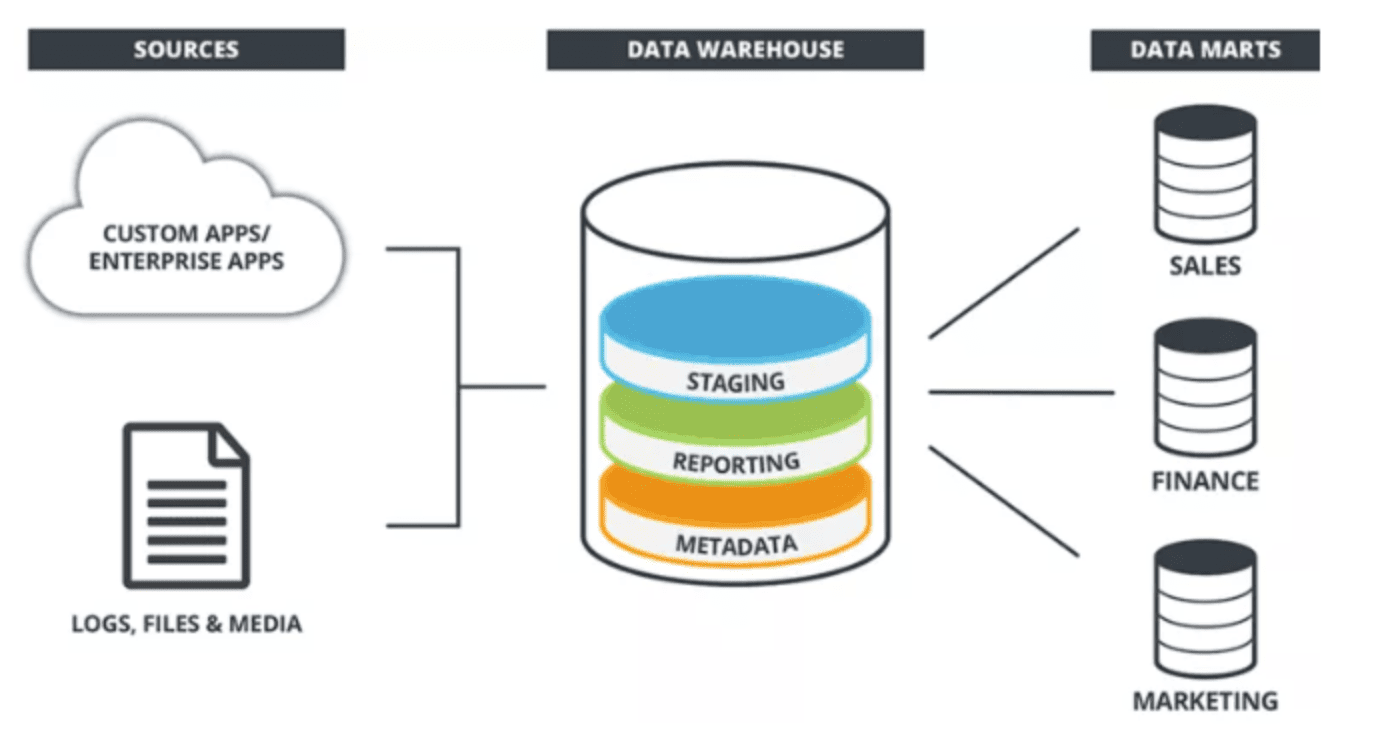
Why Do We Need a Data Warehouse?
Benefits of a Dedicated Data Warehouse
- Performance Isolation: Analytics workloads don’t impact operational systems
- Integrated View: Consolidated data from multiple sources provides a single version of truth
- Historical Analysis: Maintains historical data beyond what’s typically kept in operational systems
- Query Optimization: Specifically designed for complex analytical queries across large datasets
- Data Quality: ETL processes can clean, enrich, and validate data during ingestion
Modern enterprises need data warehouses for several key reasons:
- Business Intelligence: Decision-makers need a holistic view of business operations
- Performance: Analytical queries would cripple production databases
- Data Integration: Combining and normalizing data from disparate sources
- Historical Analysis: Keeping and analyzing historical trends over time
- Specialized Workloads: Optimizing for analytical versus transactional processing
BigQuery: Key Features and Benefits
BigQuery offers numerous features that make it a leading choice for cloud data warehousing:
1. Serverless, Fully Managed Infrastructure
BigQuery’s serverless architecture eliminates the need for database administration tasks:
- No provisioning or capacity planning
- No software patches or upgrades to manage
- Automatic scaling of resources based on query demands
- Built-in high availability and disaster recovery
-- BigQuery scales automatically to process this query
-- on terabytes of data without any infrastructure management
SELECT
product_category,
COUNT(*) as order_count,
SUM(total_amount) as revenue
FROM `mydataset.orders`
WHERE DATE(order_date) >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
GROUP BY product_category
ORDER BY revenue DESC
2. Blazing-Fast Performance
BigQuery is designed for high-performance analytics:
- Columnar storage optimized for analytical queries
- Massive parallelization across thousands of servers
- In-memory shuffle operations for complex joins and aggregations
- Smart query optimization and caching
- Automatic query planning based on data statistics
Performance Best Practices
- Use partitioning and clustering to improve query performance and reduce costs
- Apply column pruning by selecting only needed columns
- Use appropriate data types to minimize storage and improve performance
- Avoid using SELECT * in production queries
- Leverage materialized views for common query patterns
3. Flexible Data Ingestion
BigQuery supports multiple ways to load and process data:
| Ingestion Method | Best For | Features |
|---|---|---|
| Batch Loading | Large historical datasets | High throughput, supports many file formats |
| Streaming | Real-time data analysis | Sub-second availability, up to 100,000 rows/second per table |
| Dataflow ETL | Complex transformations | Unified batch and streaming, advanced data processing |
| External Tables | Data lake analytics | Query data in Cloud Storage without loading it into BigQuery |
| Data Transfer Service | SaaS data integration | Automated transfers from Google and third-party services |
-- Creating a partitioned and clustered table for optimal performance
CREATE TABLE mydataset.sales_transactions
PARTITION BY DATE(transaction_date)
CLUSTER BY customer_id, product_id
AS
SELECT * FROM mydataset.raw_sales;
4. Cost-Effective Pricing Model
BigQuery’s pricing structure includes:
- Storage: Pay only for the data you store
- $0.02 per GB per month for active storage (first 10GB free)
- $0.01 per GB per month for long-term storage
- Queries: Pay for the amount of data processed
- $5 per TB processed (first 1TB per month is free)
- Data processed is calculated based on the columns you select and the tables you query after compression
- Flat-rate pricing option: Reserved slots for predictable workloads
- Starts at $2,000/month for 100 slots
- Enterprise version for larger organizations
Cost Control Tips
While BigQuery is cost-effective, costs can add up quickly with large datasets. Consider these practices:
- Set up cost controls and query quotas to prevent unexpected charges
- Use table partitioning to query only the needed partitions
- Preview your queries with the dry-run option to estimate processing costs
- Be cautious with SELECT * - only query columns you need
- Use materialized views to cache frequent query results
- Consider flat-rate pricing for consistent, high-volume workloads
5. Enterprise-Grade Security
BigQuery provides robust security features:
- Data encryption: Automatic encryption at rest and in transit
- Access control: IAM for coarse-grained and column/row-level security for fine-grained control
- Data masking: Dynamic data masking for sensitive information
- Audit logging: Comprehensive logging of all access and queries
- VPC Service Controls: Network security perimeter
- Customer-managed encryption keys (CMEK): Bring your own keys for encryption
-- Example of column-level access control
CREATE ROW ACCESS POLICY filter_by_department
ON mydataset.employee_data
GRANT TO ('group:analysts@example.com')
FILTER USING (department = 'Marketing');
6. Advanced Analytics Capabilities
BigQuery extends beyond basic data warehousing:
BigQuery ML:
Build and deploy ML models using SQL
-- Train a machine learning model with SQL
CREATE MODEL `mydataset.customer_churn_model`
OPTIONS(model_type='logistic_reg')
AS
SELECT
IF(churn_date IS NULL, 0, 1) AS label,
customer_age,
subscription_length,
monthly_charges,
total_charges,
payment_method
FROM
`mydataset.customer_data`;
BigQuery GIS:
Geospatial analysis capabilities
-- Geospatial query example
SELECT
store_id,
store_name,
ST_DISTANCE(
ST_GEOGPOINT(store_long, store_lat),
ST_GEOGPOINT(-122.4194, 37.7749) -- San Francisco coordinates
) AS distance_meters
FROM `mydataset.store_locations`
ORDER BY distance_meters
LIMIT 10;
- BI Engine: In-memory analysis for sub-second query performance
- Data QnA: Natural language interface to query data
- Connected Sheets: Analyze billions of rows of BigQuery data in Google Sheets
BigQuery in the Data Ecosystem
BigQuery works seamlessly with other Google Cloud services and third-party tools:
Data Integration
- Google Cloud Storage: Store and query data directly from GCS
- Cloud Dataflow: Stream processing and ETL
- Pub/Sub + Dataflow: Real-time data pipelines
- Cloud Data Fusion: Code-free data integration
- Transfer Service: Scheduled data imports from various sources
Analysis and Visualization
- Looker: Enterprise BI and data applications
- Data Studio: Free visualization and dashboarding
- Connected Sheets: Analyze BigQuery data in Google Sheets
- Third-party tools: Tableau, Power BI, and many others
Development and Management
- BigQuery API/SDK: Programmatic access in various languages
- Terraform: Infrastructure as code for BigQuery resources
- dbt (data build tool): Data transformation workflows
- Airflow/Cloud Composer: Workflow orchestration
Practical Applications
BigQuery enables various enterprise use cases across industries:
Customer Analytics
-- Analyze customer purchase patterns
SELECT
user_id,
COUNT(DISTINCT transaction_id) AS transaction_count,
SUM(purchase_amount) AS total_spent,
AVG(purchase_amount) AS avg_order_value,
MIN(purchase_date) AS first_purchase,
MAX(purchase_date) AS last_purchase,
DATE_DIFF(CURRENT_DATE(), MAX(purchase_date), DAY) AS days_since_last_purchase
FROM `mydataset.purchases`
GROUP BY user_id
HAVING transaction_count > 1
ORDER BY total_spent DESC
LIMIT 1000;
Log Analytics
-- Analyze application errors by time and type
SELECT
TIMESTAMP_TRUNC(timestamp, HOUR) AS hour,
error_type,
COUNT(*) AS error_count
FROM `mydataset.application_logs`
WHERE severity = 'ERROR'
AND DATE(timestamp) >= DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
GROUP BY hour, error_type
ORDER BY hour, error_count DESC;
IoT Data Analysis
-- Analyze device telemetry data for anomalies
SELECT
device_id,
DATE(event_time) AS event_date,
AVG(temperature) AS avg_temperature,
MAX(temperature) AS max_temperature,
MIN(temperature) AS min_temperature,
STDDEV(temperature) AS temperature_stddev
FROM `mydataset.device_telemetry`
WHERE
DATE(event_time) >= DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY)
GROUP BY device_id, event_date
HAVING temperature_stddev > 10
ORDER BY temperature_stddev DESC;
Financial Analysis
-- Calculate customer lifetime value by segment
WITH customer_purchases AS (
SELECT
c.customer_id,
c.segment,
SUM(p.amount) AS total_purchases,
COUNT(DISTINCT p.order_id) AS order_count,
MIN(p.purchase_date) AS first_purchase,
MAX(p.purchase_date) AS last_purchase
FROM `mydataset.customers` c
JOIN `mydataset.purchases` p ON c.customer_id = p.customer_id
WHERE p.purchase_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 YEAR)
GROUP BY c.customer_id, c.segment
)
SELECT
segment,
COUNT(*) AS customer_count,
ROUND(AVG(total_purchases), 2) AS avg_ltv,
ROUND(AVG(order_count), 1) AS avg_orders,
ROUND(AVG(DATE_DIFF(last_purchase, first_purchase, DAY)), 1) AS avg_customer_days
FROM customer_purchases
GROUP BY segment
ORDER BY avg_ltv DESC;
Industry Examples
- E-commerce: Personalization, inventory optimization, demand forecasting
- Finance: Risk analysis, fraud detection, regulatory reporting
- Healthcare: Population health analytics, operational efficiency, clinical research
- Media: Content recommendation, audience analysis, ad performance
- Manufacturing: Supply chain optimization, predictive maintenance, quality control
Best Practices and Optimization
Schema Design
- Use nested and repeated fields to model hierarchical data efficiently
- Choose appropriate partitioning and clustering for tables
- Apply appropriate data types to save storage and improve performance
-- Example of a well-designed schema with nested and repeated fields
CREATE TABLE `mydataset.orders` (
order_id STRING,
customer_id STRING,
order_date TIMESTAMP,
status STRING,
total_amount NUMERIC,
shipping_address STRUCT<
street STRING,
city STRING,
state STRING,
zip STRING,
country STRING
>,
items ARRAY<STRUCT<
product_id STRING,
quantity INT64,
price NUMERIC,
discount NUMERIC
>>
)
PARTITION BY DATE(order_date)
CLUSTER BY customer_id;
Query Optimization
- Filter on partitioned columns to reduce data scanned
- Use approximate aggregation functions when appropriate
- Materialize intermediate results for complex multi-step analysis
- Avoid JavaScript UDFs when possible (they can’t be parallelized)
Cost Management
- Set up cost controls
- Use table expiration for temporary data
- Implement table partitioning and clustering
- Consider flat-rate pricing for predictable workloads
What’s Next?
BigQuery is a powerful platform for data warehousing and analytics, but it’s just one part of a complete data strategy. In upcoming posts, we’ll explore:
- Data ETL Process with BigQuery and Dataflow: How to build robust data pipelines
- Advanced BigQuery Features: Deep dive into ML, GIS, and BI Engine
- Real-world BigQuery Projects: Step-by-step implementation examples
- BigQuery Performance Tuning: Advanced optimization techniques


Comments