12 min to read
Database Indexing: A Comprehensive Guide
Understanding Index Types, Performance Impact, and Optimization Strategies
Overview
In databases, indexes are crucial elements that help retrieve data quickly. In large-scale databases, indexes are so important that they can determine performance, and query efficiency varies greatly depending on how indexes are designed and implemented.
This article compares the characteristics of different database index structures and explores index tuning strategies for performance optimization in real-world environments. We’ll also cover efficient index design methods, index hints, and how to use execution plans (EXPLAIN) for query performance analysis.
As data grows and user numbers increase, data access speed significantly impacts overall application performance. Therefore, indexes are essential elements for fast data retrieval and performance optimization.
What is an Index?
An index is a data structure used to quickly find specific values in a table. Like a book’s table of contents, it quickly points to where data is stored. Without an index, the database must scan the entire table to find desired values, which is highly inefficient.
Without an index → Database must scan all rows from beginning to end (Full Table Scan)
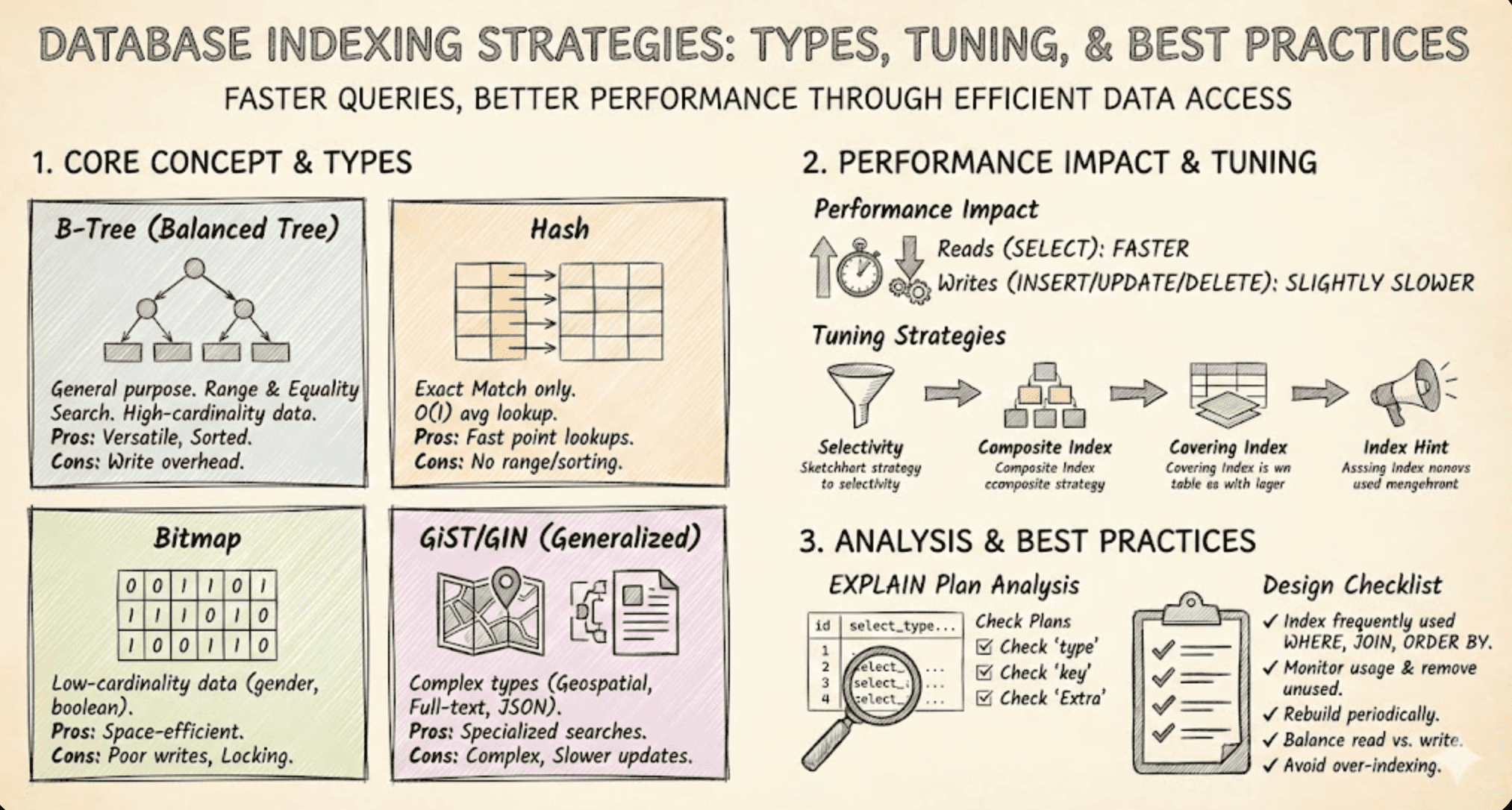
Comparison of Major Index Types
Let’s explore the different types of database indexes and their characteristics:
B-Tree Index
The B-Tree index, based on a balanced binary tree structure, is the default index type in most RDBMS systems. It excels in range searches and sorting operations, making it versatile for general-purpose indexing. However, it can experience overhead during bulk insert or delete operations.
Hash Index
Hash indexes use hash functions for data organization, providing extremely fast exact key lookups. While they offer superior performance for equality comparisons, they cannot support range queries or sorting operations. These indexes are particularly useful for cache lookups and key-value mapping scenarios.
Bitmap Index
Bitmap indexes store value existence using bitmaps, making them highly efficient for columns with few repeated values. They work well for low-cardinality columns but can suffer performance degradation with frequent DML operations. Common use cases include indexing gender, country, or boolean values.
GiST/SP-GiST Index
These PostgreSQL-specific index structures provide generic indexing capabilities. They excel at handling spatial data, approximate searches, and range trees. While offering powerful functionality, their implementation complexity can be challenging. They’re commonly used in location-based services and recommendation systems.
GIN Index
The GIN (Generalized Inverted Index) uses an inverted index structure for multi-keyword indexing. It’s particularly effective for arrays, JSON data, and full-text search operations. The trade-off is that write operations can be slower compared to other index types. GIN indexes are ideal for tag search and JSON query scenarios.
Impact of Indexes on Performance
Performance Improvement
- Faster search: Data can be retrieved using only the index without accessing the table
- Minimized sorting: ORDER BY clauses with well-designed indexes can skip sorting
- JOIN optimization: Applying indexes to join columns significantly improves join performance
Performance Degradation
- Index overuse: Too many indexes can degrade write performance (INSERT, UPDATE, DELETE)
- Low selectivity indexes are ineffective (e.g., gender, weekday with few repeated values)
- Sometimes full table scan is faster than index scan
Practical Index Tuning Methods
1. Consider Selectivity
- Selectivity = Unique values / Total rows
- Higher selectivity means better index efficiency
- Low selectivity columns have minimal index effect
2. Use Composite Indexes
- Create composite indexes for frequently used conditions together
- Index usage depends on the priority of leading columns
-- Composite index (first_name, last_name)
SELECT * FROM users WHERE first_name = 'Kim'; -- ✅ Index used
SELECT * FROM users WHERE last_name = 'Kim'; -- ❌ Index not used
3. Consider Covering Index
- If all used columns are included in the index, table access can be skipped
- MySQL: Shows as “Using index” in EXPLAIN
4. Index Monitoring
- PostgreSQL: pg_stat_user_indexes
- MySQL: SHOW INDEX FROM table_name
- Oracle: DBA_INDEXES
5. Index Rebuild and Maintenance
- Optimize indexes using ANALYZE, REINDEX, OPTIMIZE TABLE commands
- Index rebuild needed after bulk deletions
Practical Index Examples
Query Performance Improvement
-- Inefficient query (no index usage)
SELECT * FROM orders WHERE YEAR(order_date) = 2023;
-- Efficient query (avoids function, uses index)
SELECT * FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31';
Poor Index Example
-- Index on low-selectivity gender column → minimal effect
CREATE INDEX idx_gender ON users(gender);
Multi-column Index Usage
-- Create composite index (name, age order)
CREATE INDEX idx_name_age ON users(name, age);
-- Index used (order matches)
SELECT * FROM users WHERE name = 'Alice' AND age = 30;
-- Partial usage (only leading column matches)
SELECT * FROM users WHERE name = 'Alice';
-- Index not used (only trailing column condition)
SELECT * FROM users WHERE age = 30;
Tip: Composite indexes work effectively only when conditions include columns from the beginning in order.
Multiple Condition Index (Composite Index)
-- Without index, multiple conditions may cause full scan
SELECT * FROM employees WHERE department_id = 10 AND job_id = 'SA_REP';
-- Create composite index for better performance
CREATE INDEX idx_dept_job ON employees(department_id, job_id);
Note: WHERE job_id = 'SA_REP' AND department_id = 10 also performs well, but doesn't fully utilize the index range if order doesn't match.
LIKE and Wildcard Considerations
-- Index becomes useless (wildcard at start)
SELECT * FROM products WHERE name LIKE '%phone';
-- Index is used (wildcard at end)
SELECT * FROM products WHERE name LIKE 'phone%';
-- Index on name column
CREATE INDEX idx_product_name ON products(name);
OR Condition Considerations
-- OR conditions may ignore or partially use indexes
SELECT * FROM orders WHERE customer_id = 1001 OR order_status = 'SHIPPED';
-- Solution: Split using UNION to utilize indexes
SELECT * FROM orders WHERE customer_id = 1001
UNION
SELECT * FROM orders WHERE order_status = 'SHIPPED';
Function Usage and Index Inefficiency
-- Inefficient index usage (function used)
SELECT * FROM users WHERE DATE(created_at) = '2024-01-01';
-- Efficient index usage (range condition)
SELECT * FROM users WHERE created_at BETWEEN '2024-01-01 00:00:00' AND '2024-01-01 23:59:59';
-- Index on created_at column
CREATE INDEX idx_created_at ON users(created_at);
NULL Condition Index Usage
-- Some DBMS don't use indexes for NULL comparisons
SELECT * FROM employees WHERE manager_id IS NULL;
-- Need to use DBMS settings or functions (e.g., NVL, COALESCE)
Unique Constraints and Indexes
-- Use unique index for email to prevent duplicates and enable fast search
CREATE UNIQUE INDEX idx_email ON users(email);
-- Or in DDL definition
CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(255) UNIQUE
);
Covering Index Usage
-- Covering index: query can be resolved using only indexed columns
CREATE INDEX idx_order_summary ON orders(order_date, total_amount);
-- Query resolved using only index (no table access needed)
SELECT order_date, total_amount FROM orders WHERE order_date = '2024-01-01';
Advanced Index Tips
- Partial Index: Apply index only to specific conditions (useful in PostgreSQL)
- Function-based Index: Create index on specific function results (supported by Oracle, PostgreSQL)
- Descending Index: Index optimized for descending order sorting
Index Design Guide
1. Frequently Used WHERE Conditions
-- Always create index for frequently searched conditions
SELECT * FROM employees WHERE department_id = 10;
2. JOIN Condition Columns
-- Consider index for keys used in table joins
SELECT e.name, d.name FROM employees e
JOIN departments d ON e.department_id = d.department_id;
3. ORDER BY, GROUP BY Columns
-- Can improve performance for sorting or grouping
SELECT * FROM sales ORDER BY created_at DESC;
4. Leading Column Priority Strategy
-- In composite indexes, conditions must include leading columns for effective index usage
CREATE INDEX idx_user_email ON users (name, email);
-- WHERE name = 'Kim' → Used
-- WHERE email = 'kim@example.com' → Not used!
Index Hints
While DBMS automatically selects optimal indexes, developers can sometimes provide hints to use specific indexes.
MySQL Example
SELECT * FROM employees USE INDEX (idx_department) WHERE department_id = 10;
-- FORCE INDEX: Forces use of specific index
-- IGNORE INDEX: Prevents use of specific index
Execution Plan (EXPLAIN)
EXPLAIN is a tool that shows how a query will be processed before execution. It helps verify index usage, full scans, and JOIN order.
EXPLAIN SELECT * FROM employees WHERE department_id = 10;
EXPLAIN Result Analysis
| Column | Value | Description |
|---|---|---|
| id | 1 |
Query identifier (1 for simple queries) |
| select_type | SIMPLE |
Type of SELECT query (SIMPLE, PRIMARY, SUBQUERY, etc.) |
| table | employees |
Table being accessed |
| type | ref |
Access method (ref indicates index lookup) |
| key | idx_department |
Index being used |
| rows | 5 |
Estimated number of rows to examine |
| Extra | Using where |
Additional information about query execution |
Common Access Methods (type)
- ALL: Full table scan
- index: Full index scan
- range: Index range scan
- ref: Index lookup
- eq_ref: Unique index lookup
- const: Single row lookup
Common Extra Information
- Using where: WHERE clause is being applied
- Using index: Covering index is being used
- Using temporary: Temporary table is needed
- Using filesort: Additional sorting is needed
Conclusion
While indexes are the most effective means of improving read performance, they also impact write performance, making their design, use, and management crucial.
Key points to remember:
- More indexes don’t always mean better performance → impacts write performance, disk space, and maintenance costs
- Carefully analyze query patterns and apply indexes to high-selectivity columns, frequently joined columns, and ORDER BY columns
Essential points:
- Set indexes on high-selectivity columns
- Structure indexes based on frequent query conditions
- Regular index monitoring and removal of unnecessary indexes
- Balanced index design considering read/write ratio
- Create indexes appropriately on columns used in WHERE, JOIN, and ORDER BY clauses
- Analyze query execution plans using EXPLAIN to identify bottlenecks
- Sometimes use index hints to complement DB engine decisions
Efficient index strategy can be a key weapon in creating a comfortable user experience through performance optimization.

Comments