14 min to read
Large-Scale Data Processing and Data Architecture Design
Understanding OLAP, OLTP, Sharding, and Partitioning strategies
Overview
Most modern web services and enterprise systems handle massive amounts of data. Single servers or simple database structures cannot efficiently process such large-scale data, making effective data architecture design essential.
This post explores the fundamental concepts for large-scale data processing, examining the differences between OLTP and OLAP, and discussing database sharding and partitioning strategies.
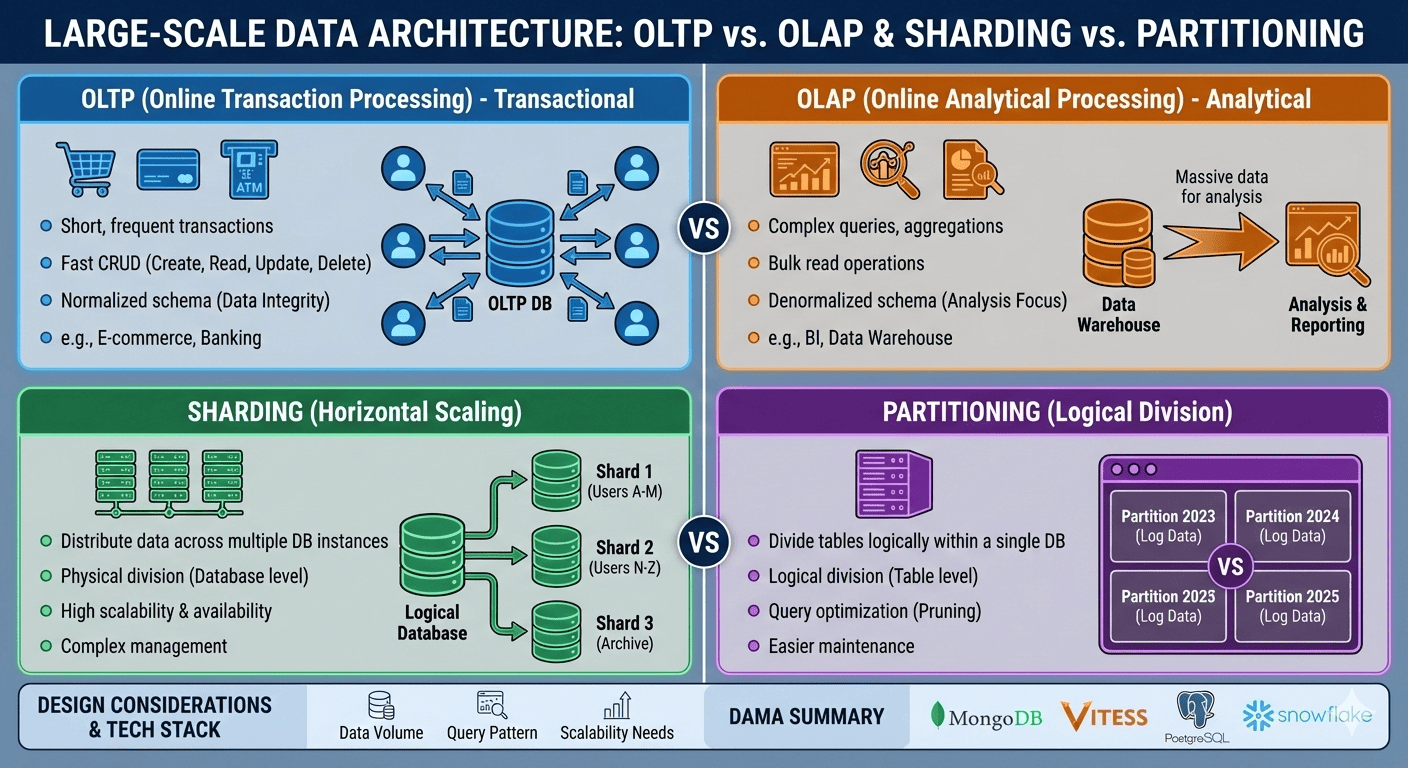
1. OLTP vs. OLAP
Understanding the distinction between these two data processing paradigms is crucial for designing appropriate data architectures.
OLTP (Online Transaction Processing)
Definition: Transaction-oriented databases optimized for fast CRUD (Create, Read, Update, Delete) operations.
Key Characteristics
- Short and frequent transactions
- Data integrity is critical
- Normalized schema usage
- Examples: E-commerce order processing, banking transaction systems
- Online shopping cart and order management
- Banking and financial transactions
- User account management systems
- Real-time inventory tracking
OLAP (Online Analytical Processing)
Definition: Analytics-focused databases designed to perform complex queries and statistics on large volumes of data.
Key Characteristics
- Multidimensional analysis capabilities
- Aggregation and grouping query focus
- Denormalized schemas (star schema, snowflake schema)
- Examples: BI tools, data warehouses, marketing reports
- Business intelligence dashboards
- Financial reporting and analysis
- Customer behavior analytics
- Sales performance tracking
OLTP vs OLAP Comparison
| Aspect | OLTP | OLAP |
|---|---|---|
| Purpose | Transaction processing | Data analysis |
| Operation Type | CRUD operations | Complex queries, aggregations |
| Performance Focus | Fast response time | Large-scale processing optimization |
| Schema Design | Normalized | Denormalized |
| Use Cases | Shopping, banking, ERP | BI, reporting, decision making |
2. Large-Scale Data Processing Strategies
To efficiently process large-scale data, horizontally scalable architectures are necessary. Sharding and partitioning strategies are the primary approaches.
Data Distribution Architecture
Sharding
Definition: A method of distributing data across multiple database instances (horizontal partitioning).
Advantages
- Performance improvement through read/write load distribution
- Database-level scalability
- Reduced single points of failure
Example Implementation
-- User data distribution based on user ID hash
-- user_0, user_1, user_2 databases
SELECT * FROM user_shard_0 WHERE user_id % 3 = 0;
SELECT * FROM user_shard_1 WHERE user_id % 3 = 1;
SELECT * FROM user_shard_2 WHERE user_id % 3 = 2;
Real-World Applications
- Facebook: Shards user data based on geographical regions
- Shopify: Divides shards by store and manages them independently for scalability and high availability
Sharding Key Considerations
- Choose fields that align well with query patterns (e.g., frequently queried user_id)
- Maintain balanced data distribution (prevent data skew)
- Avoid frequently updated or joined fields
Partitioning
Definition: A method of logically dividing tables within a single database.
Types of Partitioning
| Type | Description |
|---|---|
| Range Partitioning | Divide by date or numeric ranges |
| List Partitioning | Divide by specific value sets |
| Hash Partitioning | Distribute by hash values |
Example: Range Partitioning by Date
-- Monthly partitioning for log table
CREATE TABLE logs_2024_01 PARTITION OF logs
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
CREATE TABLE logs_2024_02 PARTITION OF logs
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');
Advantages
- Query performance optimization through partition pruning
- Simplified backup and maintenance
Partition Pruning
A DBMS optimization technique that reads only necessary partitions based on query conditions.
Example:
SELECT * FROM logs WHERE created_at >= '2024-01-01';
-- Only scans specific date partitions
Sharding vs Partitioning Comparison
| Aspect | Sharding | Partitioning |
|---|---|---|
| Scope | Database instances | Table-level partitions |
| Scalability | Horizontal scaling | Logical division |
| Operational Complexity | High (shard key management) | Relatively low |
| Use Cases | Global user distribution | Date-based log division |
3. Design Considerations Checklist
When designing large-scale data architectures, several critical factors must be evaluated.
| Consideration | Description |
|---|---|
| Data Volume | Consider distributed architecture for hundreds of GB or more |
| Query Patterns | Sharding is effective when single-key-based queries are common |
| Scaling Requirements | Pre-design for anticipated traffic surges |
| Backup/Recovery Strategy | Consider increased complexity in sharded environments |
4. Post-Sharding Operational Considerations
After implementing sharding, several operational challenges must be addressed for optimal performance.
Cross-Shard Query Challenges
In sharded environments, performance degradation can occur when querying data across different shards simultaneously.
Problem Example
-- user_id is sharded, but joining with user_logs table
SELECT u.name, l.action
FROM users u
JOIN user_logs l ON u.user_id = l.user_id
WHERE l.created_at > '2024-01-01';
Solutions
- Shard gateway for parallel query requests across multiple shards
- Data replication or pre-aggregation architectural designs
- Denormalization strategies to avoid cross-shard joins
Shard Re-balancing (Re-sharding)
Even well-designed sharding keys can experience traffic concentration over time.
Problem Scenario
- Sudden user growth in specific regions
- Uneven data distribution leading to hot spots
Solutions
- Virtual Shard concept: Separate shards from physical servers
- Flexible redistribution: Enable dynamic shard rebalancing
- Consistent hashing: Minimize data movement during rebalancing
Partitioning Best Practices
Avoiding Over-Partitioning
- Too many partitions can degrade performance (e.g., 1000+ partitions in PostgreSQL)
- Automate partition maintenance (e.g., daily log table creation with scheduled partition addition)
Maintenance Automation
-- Automated partition creation script
CREATE OR REPLACE FUNCTION create_monthly_partitions()
RETURNS void AS $$
DECLARE
start_date date;
end_date date;
BEGIN
start_date := date_trunc('month', CURRENT_DATE + interval '1 month');
end_date := start_date + interval '1 month';
EXECUTE format('CREATE TABLE IF NOT EXISTS logs_%s PARTITION OF logs
FOR VALUES FROM (%L) TO (%L)',
to_char(start_date, 'YYYY_MM'), start_date, end_date);
END;
$$ LANGUAGE plpgsql;
5. Strategy Selection Guide
Choosing between sharding and partitioning depends on specific requirements and constraints.
| Consideration Factor | Recommended Strategy |
|---|---|
| Global user base, high availability required | Sharding |
| Time-based logs, event streams | Partitioning |
| Scaling for traffic surges | Consider sharding first |
| Operational simplicity, query optimization | Partitioning |
Technology Stack Examples
| Strategy | Representative Tools |
|---|---|
| Sharding | MongoDB, Vitess (MySQL), CockroachDB, YugabyteDB |
| Partitioning | PostgreSQL, BigQuery, Redshift, Snowflake |
6. Implementation Patterns and Examples
Real-world implementation requires careful consideration of specific use cases and requirements.
Sharding Implementation Example
User-based Sharding Strategy
import hashlib
def get_shard_id(user_id, num_shards=4):
"""Calculate shard ID based on user ID hash"""
hash_value = int(hashlib.md5(str(user_id).encode()).hexdigest(), 16)
return hash_value % num_shards
def get_database_connection(user_id):
"""Get appropriate database connection for user"""
shard_id = get_shard_id(user_id)
return f"database_shard_{shard_id}"
# Usage example
user_id = 12345
db_connection = get_database_connection(user_id)
print(f"User {user_id} should use {db_connection}")
Geographic Sharding Strategy
REGION_SHARD_MAPPING = {
'us-east': 'shard_0',
'us-west': 'shard_1',
'europe': 'shard_2',
'asia': 'shard_3'
}
def get_shard_by_region(user_region):
"""Route users to appropriate shard based on region"""
return REGION_SHARD_MAPPING.get(user_region, 'shard_0')
Partitioning Implementation Example
Time-based Partitioning
-- PostgreSQL declarative partitioning
CREATE TABLE sensor_data (
id SERIAL,
sensor_id INTEGER,
measurement NUMERIC,
recorded_at TIMESTAMP NOT NULL
) PARTITION BY RANGE (recorded_at);
-- Create monthly partitions
CREATE TABLE sensor_data_2024_01 PARTITION OF sensor_data
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');
CREATE TABLE sensor_data_2024_02 PARTITION OF sensor_data
FOR VALUES FROM ('2024-02-01') TO ('2024-03-01');
Hash-based Partitioning
-- Distribute data evenly across partitions
CREATE TABLE user_activity (
user_id INTEGER,
activity_type VARCHAR(50),
timestamp TIMESTAMP
) PARTITION BY HASH (user_id);
CREATE TABLE user_activity_part_0 PARTITION OF user_activity
FOR VALUES WITH (modulus 4, remainder 0);
CREATE TABLE user_activity_part_1 PARTITION OF user_activity
FOR VALUES WITH (modulus 4, remainder 1);
7. Monitoring and Maintenance
Effective monitoring and maintenance strategies are crucial for long-term success of distributed data architectures.
Key Metrics to Monitor
Sharding Metrics
- Shard distribution balance: Monitor data volume per shard
- Cross-shard query frequency: Track queries spanning multiple shards
- Hot shard identification: Detect overloaded shards
- Connection pool utilization: Monitor connection usage per shard
Partitioning Metrics
- Partition scan efficiency: Measure partition pruning effectiveness
- Partition size distribution: Ensure balanced partition sizes
- Query performance: Track query execution times across partitions
Automation Scripts
Shard Health Check
def check_shard_health(shard_connections):
"""Monitor shard health and balance"""
health_report = {}
for shard_id, connection in shard_connections.items():
# Check connection status
try:
result = connection.execute("SELECT COUNT(*) FROM users")
health_report[shard_id] = {
'status': 'healthy',
'user_count': result.fetchone()[0]
}
except Exception as e:
health_report[shard_id] = {
'status': 'error',
'error': str(e)
}
return health_report
Partition Maintenance
-- Automated partition cleanup for old data
CREATE OR REPLACE FUNCTION cleanup_old_partitions()
RETURNS void AS $$
DECLARE
partition_name text;
BEGIN
-- Find partitions older than 1 year
FOR partition_name IN
SELECT schemaname||'.'||tablename
FROM pg_tables
WHERE tablename LIKE 'logs_%'
AND tablename < 'logs_' || to_char(CURRENT_DATE - interval '1 year', 'YYYY_MM')
LOOP
EXECUTE 'DROP TABLE IF EXISTS ' || partition_name;
RAISE NOTICE 'Dropped old partition: %', partition_name;
END LOOP;
END;
$$ LANGUAGE plpgsql;
Key Points
-
OLTP vs OLAP Understanding
- OLTP: Transaction-focused with normalized schemas
- OLAP: Analytics-focused with denormalized schemas
- Choose based on primary use case and query patterns -
Scaling Strategies
- Sharding: Horizontal distribution across database instances
- Partitioning: Logical division within single database
- Consider data volume, query patterns, and operational complexity -
Implementation Considerations
- Plan for cross-shard queries and re-balancing
- Automate partition maintenance and monitoring
- Choose appropriate technology stack for requirements
- Implement comprehensive monitoring and alerting
Conclusion
In large-scale data processing systems, simple schemas or single-node operations have clear limitations.
Understanding the differences between transaction-focused OLTP and analytics-focused OLAP, and appropriately combining sharding and partitioning strategies based on specific situations, is crucial. Ultimately, systems must be designed considering data structure, query types, and maintenance convenience to implement architectures that satisfy both performance and scalability requirements.
Moving forward, these foundational structures will evolve to integrate various architectures including data warehouses, data lakes, and real-time streaming processing.
Future Evolution
- Hybrid architectures combining OLTP and OLAP capabilities
- Cloud-native solutions with auto-scaling and serverless capabilities
- Real-time analytics integration with streaming data processing
- Multi-cloud and edge computing considerations for global scale
The key is to start with solid fundamentals in data architecture design and evolve the system as requirements and technologies advance.
References
- OLTP vs OLAP Differences
- AWS Redshift MPP Architecture
- Microsoft Azure Sharding Patterns
- Google BigQuery Partitioned Tables
- Sharding vs Partitioning
- Facebook Logging Infrastructure at Scale
- Designing Data-Intensive Applications - Martin Kleppmann
- Uber Schemaless - Uber’s Approach to Managing Sharded MySQL
- Vitess - YouTube’s MySQL Sharding Solution
- PostgreSQL Partitioning

Comments