11 min to read
Data ETL Pipeline Components and Architecture Guide
A comprehensive guide to building scalable ETL pipelines with Hadoop ecosystem
Overview
ETL (Extract, Transform, Load) pipelines are essential data engineering processes that extract, transform, and load large volumes of data for data analysis, machine learning, and business insights.
This post will explain the components of Hadoop-based ETL pipelines and the key technology stack for each stage.
What is an ETL Pipeline?
An ETL pipeline is a data processing workflow that collects, transforms, and transfers data to data storage systems.
Most implementations leverage the Hadoop Ecosystem for big data processing, while real-time streaming data often combines technologies like Kafka and Flink.
ETL vs ELT Differences
- ETL → Data transformation occurs before data loading (traditional approach)
- ELT → Data is loaded first, then transformed (commonly used in cloud data warehouses)
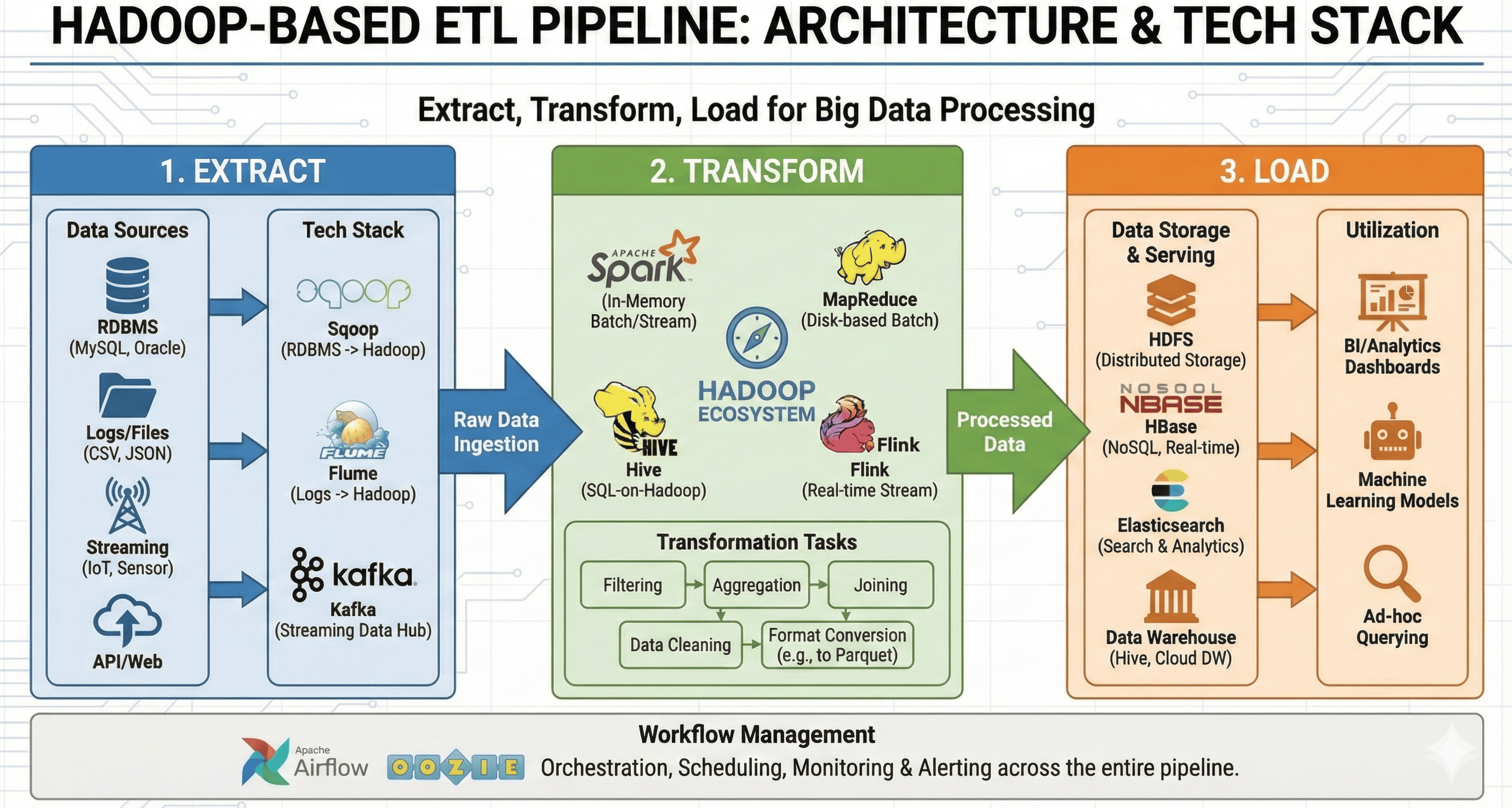
ETL Pipeline Core Components
ETL pipelines consist of three fundamental stages that work together to process data efficiently.
Data Flow Architecture
1. Extract (Data Extraction)
The extraction stage involves collecting data from various sources and systems.
Major Data Sources
- Databases: MySQL, PostgreSQL, Oracle, SQL Server
- File Systems: CSV, JSON, Parquet formats
- APIs and Web Data: REST API, GraphQL
- Streaming Data: Kafka, Flume
- Log Files and Sensor Data: Fluentd, Logstash, IoT devices
Recommended Technology Stack
| Technology | Role and Purpose |
|---|---|
| Sqoop | Data transfer from relational databases to Hadoop (HDFS) |
| Flume | Log data collection and transmission |
| Kafka | Real-time streaming data collection and message queuing |
| NiFi | GUI-based data flow automation and orchestration |
2. Transform (Data Transformation and Processing)
The transformation stage processes extracted data to make it suitable for analysis. This includes deduplication, filtering, joining, aggregation, and format conversion.
Recommended Technology Stack
| Technology | Role and Purpose |
|---|---|
| Apache Spark | In-memory distributed processing (Batch + Stream) |
| MapReduce | Hadoop's default distributed processing approach (batch) |
| Hive | SQL-based data transformation and querying |
| Pig | Script-based data transformation |
| Flink | Real-time data transformation and stream processing |
| Dask | Python-based distributed processing |
- Spark is significantly faster and more efficient than traditional MapReduce
- Use Hive for SQL-based processing, Flink for real-time processing
3. Load (Data Storage and Utilization)
The loading stage stores transformed data in appropriate storage systems, making it available for analysis and utilization through data warehouses, data lakes, NoSQL databases, and search engines.
Recommended Technology Stack
| Technology | Role and Purpose |
|---|---|
| HDFS | Hadoop-based distributed storage system |
| HBase | NoSQL storage for real-time query requirements |
| Cassandra | NoSQL database for large-scale data storage |
| Elasticsearch | Search and log analysis capabilities |
| Redshift, BigQuery | Cloud-based data warehouses |
| Snowflake | Modern cloud data warehouse platform |
ETL Pipeline Design Considerations
When designing ETL pipelines, several critical factors must be considered to ensure scalability, performance, and reliability.
Key Design Factors
1. Data Volume (Big Data)
- Distributed Processing: As data volume increases, distributed systems like Hadoop and Spark become essential
- Scalable Storage: Requires expandable storage solutions like HDFS and S3
2. Real-time vs Batch Processing
- Batch Processing: Spark, MapReduce, Hive for scheduled data processing
- Streaming Processing: Kafka, Flink, Spark Streaming for real-time data processing
3. Scalability Requirements
- Distributed Environments: Use Spark, Kubernetes, and Airflow for scaling
- Cloud Solutions: Leverage AWS Glue, Google Dataflow, Azure Data Factory
4. Error Handling and Monitoring
- Workflow Management: Use Airflow or Prefect for orchestration
- Real-time Monitoring: Implement Prometheus + Grafana
- Log Analysis: Deploy Elasticsearch + Kibana
ETL Pipeline Example (Hadoop & Spark Based)
This section demonstrates a practical ETL pipeline implementation using the Hadoop ecosystem.
ETL Process Example
Scenario: E-commerce transaction data processing
- Extract: Import transactions table data from MySQL and store in HDFS
- Transform: Use Spark to clean data and filter users with high purchase amounts
- Load: Store transformed data in HBase for fast query support
ETL Workflow Implementation
Basic ETL Commands
Detailed ETL Process Implementation
This section provides comprehensive examples and additional use cases for each ETL stage.
Extract Stage (MySQL → HDFS)
Objective
- Transfer MySQL transactions table data to HDFS
- Use Sqoop for relational database to Hadoop data migration
Basic Implementation
Explanation:
jdbc:mysql://dbserver:3306/ecommerce→ MySQL database connectiontransactions→ Source table name/data/transactions→ HDFS destination directory-m 1→ Single mapper usage (can enable parallel processing)
Advanced Use Cases
Filtered Data Extraction (Last 30 Days)
High-Volume Data Processing (4 Parallel Mappers)
Using multiple mappers significantly improves data extraction speed for large datasets!
Transform Stage (Spark Data Processing)
Objective
- Use Spark to filter users with high purchase amounts
- Store filtered data back to HDFS for further processing
Implementation Command
spark-submit --class MainApp transform.py
Python Spark Script Example
from pyspark.sql import SparkSession
# Create Spark session
spark = SparkSession.builder.appName("HighValueCustomers").getOrCreate()
# Read data from HDFS
df = spark.read.option("header", "true").csv("hdfs:///data/transactions")
# Filter data (purchase_amount > 1000)
high_value_customers = df.filter(df.purchase_amount > 1000)
# Save filtered data
high_value_customers.write.csv("hdfs:///data/high_value_customers", header=True)
spark.stop()
Process Explanation:
- Create SparkSession → Read CSV data from HDFS
- Apply filtering → Keep only records where purchase_amount > 1000
- Save results back to HDFS
Advanced Use Cases
Parquet Format Conversion (Performance Optimization)
high_value_customers.write.parquet("hdfs:///data/high_value_customers_parquet")
Advanced Filtering with Spark SQL
df.createOrReplaceTempView("transactions")
high_value_customers = spark.sql("""
SELECT * FROM transactions
WHERE purchase_amount > 1000 AND region = 'US'
""")
Using Parquet format and Spark SQL provides significantly better performance optimization!
Load Stage (HDFS → HBase Storage)
Objective
- Store filtered data in HBase for real-time analysis capabilities
- HBase is optimal for data requiring fast query performance
Basic HBase Operations
hbase shell <<EOF
create 'high_value_customers', 'info'
put 'high_value_customers', 'user123', 'info:purchase', '1000'
EOF
Explanation:
create 'high_value_customers', 'info'→ Create HBase tableput 'high_value_customers', 'user123', 'info:purchase', '1000'→ Store user data
Advanced Use Case: Direct Spark to HBase Loading
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
import happybase
# Create Spark session
spark = SparkSession.builder.appName("LoadToHBase").getOrCreate()
# HBase connection
connection = happybase.Connection('hbase-master')
table = connection.table('high_value_customers')
# Read data from HDFS
df = spark.read.parquet("hdfs:///data/high_value_customers_parquet")
# Store in HBase
for row in df.collect():
table.put(
row['user_id'].encode(),
{b'info:purchase': str(row['purchase_amount']).encode()}
)
connection.close()
This approach enables direct loading of Spark-filtered data into HBase!
Final ETL Workflow Summary
| Stage | Technology | Description |
|---|---|---|
| Extract | Sqoop | Transfer data from MySQL to HDFS |
| Transform | Spark | Filter records with purchase_amount > 1000 |
| Load | HBase | Store filtered data in real-time analysis database |
Automating this ETL process with Kubernetes, Helm, and Airflow creates an even more powerful data pipeline!
Modern ETL Trends and Technologies
The data engineering landscape continues to evolve with cloud-native solutions and modern architectures.
Current Industry Trends
ELT Approach with Cloud Data Warehouses
- Snowflake, BigQuery: Cloud-native data warehouses supporting ELT patterns
- Advantages: Leverage cloud compute power for transformations
- Use Cases: When transformation logic is complex and benefits from warehouse optimization
Spark + Airflow Automation
- Data Pipeline Automation: Orchestrate complex workflows
- Benefits: Scheduling, monitoring, and error handling
- Integration: Seamless integration with Kubernetes environments
Real-time Processing Evolution
- Stream Processing: Kafka + Flink + Elasticsearch combinations
- Lambda Architecture: Batch and stream processing in parallel
- Kappa Architecture: Stream-first approach with unified processing
Technology Selection Guide
- Batch Processing: Hadoop + Spark + Airflow
- Real-time Streaming: Kafka + Flink + Elasticsearch
- Cloud Data Warehouse: Snowflake, Redshift, BigQuery
- Hybrid Approach: Combine batch and streaming for comprehensive coverage
Implementation Best Practices
When building production ETL pipelines, following established best practices ensures reliability and maintainability.
Design Principles
Data Quality and Validation
- Schema Validation: Enforce data types and constraints
- Data Profiling: Monitor data quality metrics
- Error Handling: Implement comprehensive error recovery
Performance Optimization
- Partitioning Strategy: Optimize data layout for query performance
- Compression: Use appropriate compression algorithms
- Caching: Implement intelligent caching for frequently accessed data
Monitoring and Observability
- Pipeline Monitoring: Track execution times and success rates
- Data Lineage: Maintain visibility into data flow and transformations
- Alerting: Set up proactive alerts for pipeline failures
Key Points
-
Core Process
- Extract: Collect data from various sources
- Transform: Process and clean data for analysis
- Load: Store data in appropriate storage systems
- Essential for data analysis, ML, and business insights -
Technology Stack
- Hadoop ecosystem provides scalability and performance
- Spark offers superior performance over traditional MapReduce
- Cloud-friendly tools like Airflow enable automation
- Modern trend toward ELT with cloud data warehouses -
Architecture Decisions
- Consider data volume, velocity, and variety
- Choose between batch and real-time processing
- Plan for scalability and error handling
- Implement comprehensive monitoring and alerting
Conclusion
ETL pipelines are fundamental data engineering processes that collect (Extract) → transform (Transform) → store (Load) data for analytics and insights.
When building Hadoop-based solutions, technologies like HDFS, Spark, Hive, and Kafka provide the scalability and performance needed for modern data workloads.
Current trends favor cloud-native approaches with Spark, Flink, and Airflow for automated data pipeline orchestration.
Latest Technology Trends
- ELT approach using cloud data warehouses like Snowflake and BigQuery
- Data pipeline automation with Spark + Airflow integration
- Real-time processing capabilities with modern streaming technologies
Recommendations for ETL Pipeline Development
- Batch Processing: Hadoop + Spark + Airflow
- Real-time Streaming: Kafka + Flink + Elasticsearch
- Cloud Data Warehouse: Snowflake, Redshift, BigQuery
The choice depends on your specific requirements for data volume, processing speed, and infrastructure preferences.

Comments