62 min to read
Mastering MLOps Essential Libraries: NumPy, Pandas, and Scikit-Learn Complete Guide
From data pipelines to model deployment - Essential tools for MLOps engineers
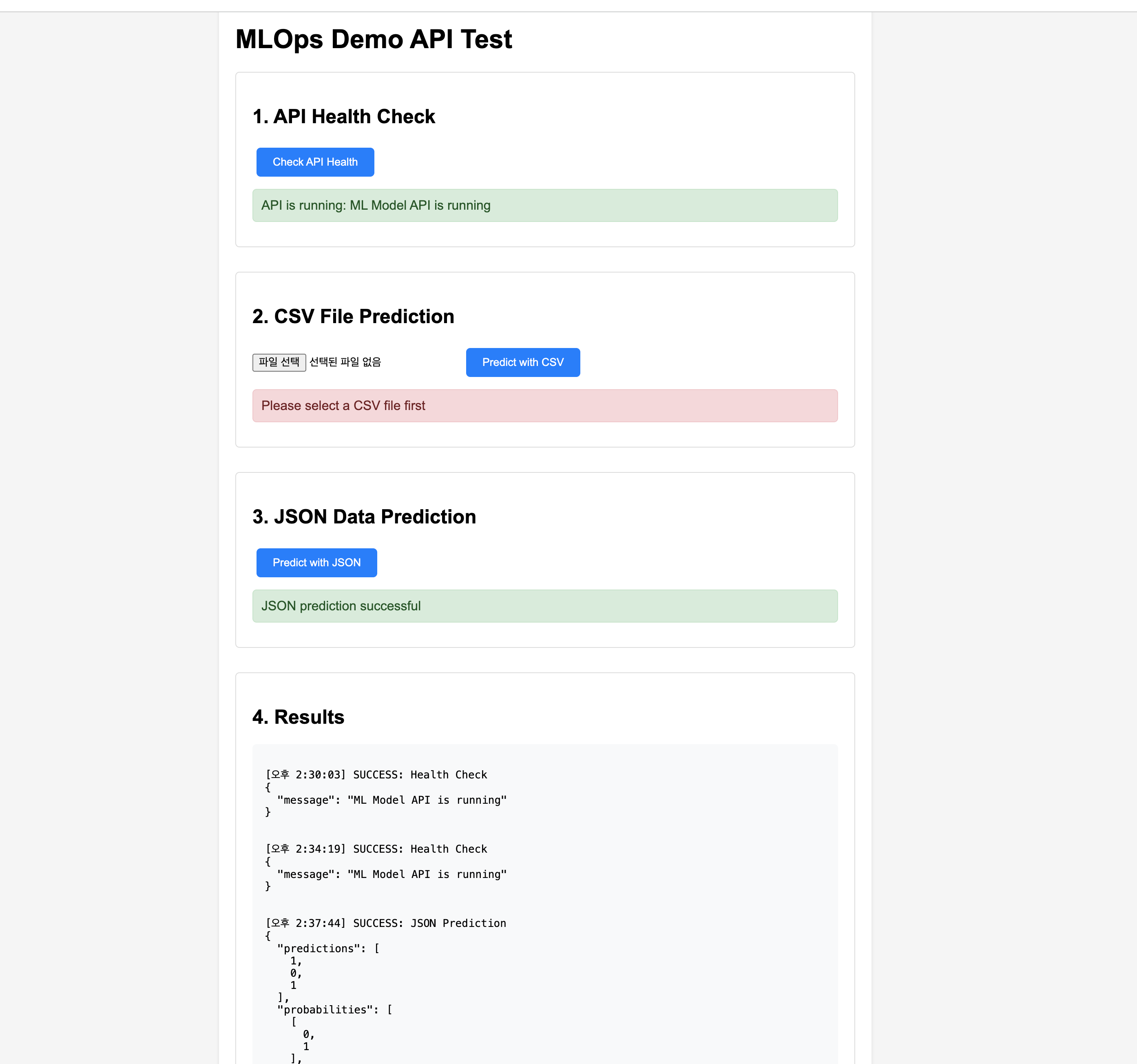
Table of Contents
- Introduction
- MLOps Pipeline Architecture
- NumPy: High-Performance Foundation
- Pandas: Data Pipeline Powerhouse
- Scikit-Learn: Complete ML Pipeline
- Hands-on: Local MLOps Pipeline
- Production Deployment (FastAPI + Docker + K8s)
- Monitoring & Automation
- Key Points & Conclusion
- References
Introduction to MLOps Fundamentals
“Data is as important as code.” As AI/ML becomes central to modern software development, traditional DevOps engineers must expand into MLOps territory.
This comprehensive guide explores how NumPy, Pandas, and Scikit-Learn form the backbone of production MLOps workflows, enabling efficient data processing, model training, and deployment strategies.
Why These Three Libraries Matter
NumPy, Pandas, and Scikit-Learn aren’t just data science tools—they’re the foundation of modern MLOps infrastructure:
- NumPy: High-performance numerical computing engine powering all ML frameworks
- Pandas: Data manipulation and ETL backbone for feature engineering
- Scikit-Learn: Complete machine learning pipeline from experimentation to production
- Production Ready: Battle-tested libraries used by major tech companies worldwide
- Ecosystem Integration: Seamless compatibility with Docker, Kubernetes, and cloud platforms
- Community Support: Extensive documentation, tutorials, and community resources
MLOps Pipeline Architecture
Understanding how these libraries fit into the MLOps workflow is crucial for building efficient, scalable machine learning systems. This section maps out where each library excels in the typical MLOps pipeline and how they work together to create robust data-driven applications.
Library Roles in MLOps Workflow
Data Sources] B -.-> B1[NumPy
Transformations] C -.-> C1[Scikit-Learn
Models] D -.-> D1[Scikit/Pandas
Metrics] E -.-> E1[joblib + API
Serving] style A fill:#a5d6a7,stroke:#333,stroke-width:1px style B fill:#64b5f6,stroke:#333,stroke-width:1px style C fill:#ffcc80,stroke:#333,stroke-width:1px style D fill:#ce93d8,stroke:#333,stroke-width:1px style E fill:#ef9a9a,stroke:#333,stroke-width:1px
| Pipeline Stage | Primary Library | Key Responsibilities |
|---|---|---|
| Data Collection | Pandas | Reading from various sources (CSV, JSON, SQL, Parquet), data validation, initial exploration |
| Preprocessing | NumPy + Pandas | Numerical transformations, feature engineering, data cleaning, normalization |
| Model Training | Scikit-Learn | Algorithm selection, hyperparameter tuning, cross-validation, model fitting |
| Evaluation | All Three | Performance metrics calculation, model comparison, result visualization |
| Deployment | joblib + FastAPI | Model serialization, API serving, containerization, monitoring |
NumPy: High-Performance Foundation for ML Operations
NumPy serves as the numerical computing foundation for the entire Python data science ecosystem. Its efficient array operations and mathematical functions make it indispensable for high-performance machine learning workflows, providing the speed and reliability needed for production systems.
Why NumPy is Critical for MLOps
The Performance Engine of ML
NumPy isn’t just a numerical library—it’s the performance engine behind modern machine learning operations:
- Speed: C-implemented vectorized operations are 10-100x faster than pure Python
- Memory Efficiency: Homogeneous arrays with contiguous memory layout
- Universal Compatibility: Foundation for TensorFlow, PyTorch, Scikit-Learn, and other ML libraries
- Broadcasting: Efficient operations on arrays of different shapes
- Mathematical Functions: Comprehensive collection of mathematical, statistical, and linear algebra operations
Core NumPy Capabilities
| Feature Category | Key Functions | MLOps Applications |
|---|---|---|
| Array Operations | reshape, concatenate, split, stack | Data preprocessing, batch processing, feature transformation |
| Mathematical Functions | sin, cos, exp, log, sqrt | Feature engineering, activation functions, transformations |
| Statistical Operations | mean, std, percentile, histogram | Data analysis, normalization, outlier detection |
| Linear Algebra | dot, matmul, linalg.inv, svd | Matrix operations, dimensionality reduction, optimization |
| Random Sampling | random.normal, random.choice, seed | Data augmentation, train/test splits, reproducible experiments |
Practical Implementation Examples
Real-time Log Data Normalization
Processing server latency logs for anomaly detection:
import numpy as np
def normalize_latency_data(latencies):
"""Normalize server response time logs for outlier detection"""
latencies = np.array(latencies)
# Z-score normalization
normalized = (latencies - np.mean(latencies)) / np.std(latencies)
# Apply 3-sigma rule for outlier clipping
clipped = np.clip(normalized, -3, 3)
return clipped
# Example: Microservice response times (ms)
response_times = [15, 20, 500, 30, 22, 18, 25, 1000, 19]
cleaned_data = normalize_latency_data(response_times)
print(f"Normalized data: {cleaned_data}")
Vectorized Operations for Performance Optimization
Comparing vectorized vs traditional approaches:
# Inefficient approach (pure Python)
def slow_distance_calculation(points1, points2):
distances = []
for p1, p2 in zip(points1, points2):
dist = ((p1[0] - p2[0])**2 + (p1[1] - p2[1])**2)**0.5
distances.append(dist)
return distances
# Efficient approach (NumPy vectorization)
def fast_distance_calculation(points1, points2):
p1 = np.array(points1)
p2 = np.array(points2)
return np.sqrt(np.sum((p1 - p2)**2, axis=1))
# Performance benchmark
import time
points1 = [(i, i) for i in range(100000)]
points2 = [(i+1, i+1) for i in range(100000)]
# NumPy approach is 10-50x faster
MLOps Production Tips
- Memory Efficiency: Use np.memmap for processing datasets larger than available RAM
- Type Optimization: Choose float32 vs float64 to reduce memory usage by 50%
- GPU Acceleration: Leverage CuPy library to run NumPy code on GPU for massive datasets
- Vectorization: Replace Python loops with NumPy operations for 10-100x speed improvements
- Broadcasting: Use NumPy's broadcasting rules to avoid explicit loops and temporary arrays
Pandas: Data Pipeline Powerhouse
Pandas serves as the backbone of data manipulation and ETL processes in MLOps workflows. Its ability to handle diverse data formats and perform complex transformations makes it indispensable for feature engineering, data cleaning, and preparing datasets for machine learning models.
Why Pandas is Essential for MLOps
The Data Manipulation Engine
Pandas isn’t just a data analysis tool—it’s the data manipulation engine powering MLOps workflows:
- Format Versatility: Native support for CSV, JSON, Parquet, SQL, Excel, and more
- Data Operations: Powerful grouping, joining, pivoting, and aggregation capabilities
- Time Series Support: Specialized functionality for temporal data analysis
- Missing Data Handling: Robust methods for dealing with incomplete datasets
- Performance: Optimized operations using underlying NumPy arrays
- Integration: Seamless compatibility with scikit-learn and other ML libraries
Core Pandas Capabilities
| Feature Category | Key Functions | MLOps Applications |
|---|---|---|
| Data I/O | read_csv, read_json, read_sql, to_parquet | Data ingestion, feature store integration, model artifact storage |
| Data Cleaning | dropna, fillna, replace, duplicated | Data quality assurance, preprocessing automation |
| Transformations | groupby, merge, pivot, apply | Feature engineering, data aggregation, business logic implementation |
| Time Series | resample, rolling, shift, date_range | Temporal feature extraction, trend analysis, forecasting preparation |
| Statistical Operations | describe, corr, value_counts, quantile | Data profiling, exploratory data analysis, feature selection |
Practical Implementation Examples
Feature Store Integration Pipeline
Building a robust data pipeline that connects multiple data sources:
import pandas as pd
from datetime import datetime, timedelta
import sqlalchemy
import boto3
class FeaturePipeline:
def __init__(self, config):
self.config = config
self.db_engine = sqlalchemy.create_engine(config['database_url'])
self.s3_client = boto3.client('s3')
def extract_user_features(self, user_ids, date_range):
"""Extract and combine user features from multiple data sources"""
# 1. Extract user activity from S3 (Parquet files)
activity_df = self._extract_activity_data(date_range)
# 2. Extract transaction data from PostgreSQL
transaction_df = self._extract_transaction_data(user_ids, date_range)
# 3. Extract product interaction from Redis/MongoDB
interaction_df = self._extract_interaction_data(user_ids, date_range)
# 4. Combine and engineer features
return self._create_feature_matrix(activity_df, transaction_df, interaction_df)
def _extract_activity_data(self, date_range):
"""Extract user activity logs from S3"""
start_date, end_date = date_range
# Read multiple Parquet files efficiently
file_pattern = f"s3://ml-datalake/user-activity/year={start_date.year}/month={start_date.month:02d}/*.parquet"
activity_df = pd.read_parquet(file_pattern,
filters=[('event_date', '>=', start_date),
('event_date', '<=', end_date)])
# Data quality checks
activity_df = activity_df.dropna(subset=['user_id', 'event_type'])
activity_df['session_duration'] = pd.to_numeric(activity_df['session_duration'], errors='coerce')
return activity_df
def _extract_transaction_data(self, user_ids, date_range):
"""Extract transaction data from PostgreSQL"""
start_date, end_date = date_range
query = """
SELECT
user_id,
transaction_date,
amount,
category,
payment_method,
is_successful
FROM transactions
WHERE user_id = ANY(%(user_ids)s)
AND transaction_date BETWEEN %(start_date)s AND %(end_date)s
AND is_successful = true
"""
transaction_df = pd.read_sql(query,
con=self.db_engine,
params={
'user_ids': user_ids,
'start_date': start_date,
'end_date': end_date
})
# Convert data types and handle missing values
transaction_df['transaction_date'] = pd.to_datetime(transaction_df['transaction_date'])
transaction_df['amount'] = pd.to_numeric(transaction_df['amount'], errors='coerce')
return transaction_df
def _create_feature_matrix(self, activity_df, transaction_df, interaction_df):
"""Engineer features from raw data"""
# User activity features
activity_features = activity_df.groupby('user_id').agg({
'session_duration': ['mean', 'std', 'count', 'sum'],
'page_views': ['sum', 'mean'],
'clicks': ['sum', 'mean'],
'scroll_depth': ['mean', 'max']
}).round(2)
# Flatten column names
activity_features.columns = ['_'.join(col).strip() for col in activity_features.columns]
# Calculate engagement metrics
activity_features['avg_ctr'] = (
activity_features['clicks_sum'] /
(activity_features['page_views_sum'] + 1)
)
activity_features['engagement_score'] = (
activity_features['session_duration_mean'] *
activity_features['avg_ctr'] *
activity_features['scroll_depth_mean']
)
# Transaction features
transaction_features = transaction_df.groupby('user_id').agg({
'amount': ['sum', 'mean', 'count', 'std'],
'category': lambda x: x.nunique(),
'payment_method': lambda x: x.mode().iloc[0] if len(x) > 0 else 'unknown'
})
transaction_features.columns = ['_'.join(col).strip() for col in transaction_features.columns]
# Time-based features
transaction_df['hour'] = transaction_df['transaction_date'].dt.hour
transaction_df['day_of_week'] = transaction_df['transaction_date'].dt.dayofweek
time_features = transaction_df.groupby('user_id').agg({
'hour': lambda x: x.mode().iloc[0] if len(x) > 0 else 12, # Preferred shopping hour
'day_of_week': lambda x: x.mode().iloc[0] if len(x) > 0 else 0 # Preferred shopping day
})
time_features.columns = ['preferred_hour', 'preferred_day']
# Combine all features
feature_matrix = activity_features.join([transaction_features, time_features], how='outer')
# Handle missing values with business logic
feature_matrix = feature_matrix.fillna({
'session_duration_mean': 0,
'clicks_sum': 0,
'amount_sum': 0,
'engagement_score': 0
})
# Add derived features
feature_matrix['is_high_value'] = (feature_matrix['amount_sum'] > feature_matrix['amount_sum'].quantile(0.8)).astype(int)
feature_matrix['is_frequent_user'] = (feature_matrix['session_duration_count'] > 10).astype(int)
return feature_matrix
# Example usage
config = {
'database_url': 'postgresql://user:pass@localhost:5432/mlops',
's3_bucket': 'ml-datalake',
'redis_host': 'localhost'
}
pipeline = FeaturePipeline(config)
user_list = [1001, 1002, 1003, 1004, 1005]
date_range = (datetime.now() - timedelta(days=30), datetime.now())
features = pipeline.extract_user_features(user_list, date_range)
print(f"Feature matrix shape: {features.shape}")
print(f"Features: {list(features.columns)}")
Real-time Data Stream Processing
Processing streaming data for real-time feature computation:
import pandas as pd
from kafka import KafkaConsumer
import json
import redis
from collections import deque
from datetime import datetime, timedelta
class RealTimeFeatureProcessor:
def __init__(self, kafka_config, redis_client):
self.consumer = KafkaConsumer(
'user-events',
**kafka_config,
value_deserializer=lambda m: json.loads(m.decode('utf-8'))
)
self.redis_client = redis_client
self.window_size = timedelta(minutes=5)
self.feature_buffer = deque(maxlen=10000) # Circular buffer for memory efficiency
def process_stream(self):
"""Process real-time event stream and maintain feature windows"""
for message in self.consumer:
event_data = message.value
# Convert to DataFrame for consistent processing
event_df = pd.DataFrame([event_data])
event_df['timestamp'] = pd.to_datetime(event_df['timestamp'])
# Add to buffer
self.feature_buffer.append(event_data)
# Calculate windowed features
current_time = datetime.now()
window_start = current_time - self.window_size
# Filter recent events
recent_events = [
event for event in self.feature_buffer
if pd.to_datetime(event['timestamp']) > window_start
]
if recent_events:
recent_df = pd.DataFrame(recent_events)
features = self._calculate_windowed_features(recent_df)
# Store features in Redis for real-time serving
self._store_features_redis(features)
def _calculate_windowed_features(self, df):
"""Calculate features over a time window"""
# Ensure proper data types
df['timestamp'] = pd.to_datetime(df['timestamp'])
df['page_views'] = pd.to_numeric(df['page_views'], errors='coerce').fillna(0)
df['clicks'] = pd.to_numeric(df['clicks'], errors='coerce').fillna(0)
# Group by user and calculate features
user_features = df.groupby('user_id').agg({
'page_views': ['sum', 'count'],
'clicks': 'sum',
'session_duration': 'mean',
'timestamp': 'count' # Event frequency
})
# Flatten columns
user_features.columns = ['_'.join(col).strip() for col in user_features.columns]
# Add time-based features
current_hour = datetime.now().hour
user_features['current_hour'] = current_hour
user_features['is_business_hours'] = (9 <= current_hour <= 17).astype(int)
# Calculate rates
user_features['click_rate'] = (
user_features['clicks_sum'] /
(user_features['page_views_sum'] + 1)
)
user_features['events_per_minute'] = (
user_features['timestamp_count'] / 5 # 5-minute window
)
return user_features
def _store_features_redis(self, features):
"""Store computed features in Redis with TTL"""
for user_id in features.index:
feature_dict = features.loc[user_id].to_dict()
# Store with 10-minute TTL
key = f"user_features:{user_id}"
self.redis_client.hmset(key, feature_dict)
self.redis_client.expire(key, 600) # 10 minutes
# Production deployment example
def deploy_stream_processor():
kafka_config = {
'bootstrap_servers': ['kafka1:9092', 'kafka2:9092'],
'group_id': 'feature-processor',
'auto_offset_reset': 'latest',
'enable_auto_commit': True,
'value_deserializer': lambda m: json.loads(m.decode('utf-8'))
}
redis_client = redis.Redis(
host='redis-cluster.example.com',
port=6379,
decode_responses=True
)
processor = RealTimeFeatureProcessor(kafka_config, redis_client)
try:
processor.process_stream()
except KeyboardInterrupt:
print("Shutting down stream processor...")
except Exception as e:
print(f"Error in stream processing: {e}")
# Add error handling and retry logic
if __name__ == "__main__":
deploy_stream_processor()
MLOps Production Tips
Performance and scalability best practices for MLOps:
- Format Optimization: Use Parquet format for 5-10x faster I/O compared to CSV
- Memory Management: Use categorical dtypes and optimize data types to reduce memory usage
- Chunk Processing: Process large datasets in chunks to avoid memory overflow
- Parallel Processing: Leverage Dask for distributed computing when datasets exceed single-machine capacity
- Data Validation: Implement Great Expectations for automated data quality checks
- Caching Strategy: Cache intermediate results and use efficient storage formats
Scikit-Learn: Complete Machine Learning Pipeline Framework
Scikit-Learn provides a unified, production-ready framework for building complete machine learning pipelines. Its consistent API design and powerful pipeline patterns enable seamless workflows from experimentation to deployment, making it the gold standard for traditional machine learning tasks.
Why Scikit-Learn is Central to MLOps
Scikit-Learn isn’t just a machine learning library—it’s the complete ML ecosystem for MLOps:
- Consistent API: Uniform fit(), predict(), transform() interface across all components
- Pipeline Architecture: Combines preprocessing and modeling into single, deployable objects
- Model Selection: Built-in cross-validation and hyperparameter tuning capabilities
- Production Ready: Robust serialization with joblib for model persistence
- Extensive Algorithms: Comprehensive collection of supervised and unsupervised learning algorithms
- Integration Friendly: Seamless compatibility with NumPy, Pandas, and deployment frameworks
Core Scikit-Learn Components
| Component Category | Key Classes | MLOps Applications |
|---|---|---|
| Preprocessing | StandardScaler, OneHotEncoder, LabelEncoder | Feature normalization, categorical encoding, data transformation |
| Models | RandomForest, SVM, LogisticRegression, XGBoost | Classification, regression, prediction tasks |
| Pipeline | Pipeline, ColumnTransformer, FeatureUnion | Workflow automation, reproducible preprocessing |
| Model Selection | GridSearchCV, RandomizedSearchCV, cross_val_score | Hyperparameter tuning, model validation, performance estimation |
| Metrics | accuracy_score, precision_recall_curve, roc_auc_score | Model evaluation, performance monitoring, A/B testing |
Production-Ready Implementation Examples
Complete ML Pipeline with Best Practices
Building a robust, production-ready machine learning pipeline:
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder, LabelEncoder
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.metrics import classification_report, confusion_matrix
import joblib
import pandas as pd
import numpy as np
from datetime import datetime
import logging
class ProductionMLPipeline:
def __init__(self, config=None):
self.config = config or self._default_config()
self.pipeline = None
self.is_trained = False
self.training_metadata = {}
self.logger = self._setup_logging()
def _default_config(self):
"""Default configuration for the ML pipeline"""
return {
'model_type': 'random_forest',
'random_state': 42,
'test_size': 0.2,
'cv_folds': 5,
'n_jobs': -1,
'hyperparameter_tuning': True
}
def _setup_logging(self):
"""Configure logging for the pipeline"""
logger = logging.getLogger(__name__)
logger.setLevel(logging.INFO)
if not logger.handlers:
handler = logging.StreamHandler()
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
handler.setFormatter(formatter)
logger.addHandler(handler)
return logger
def build_pipeline(self, feature_config):
"""Build a complete ML pipeline with preprocessing and modeling"""
numeric_features = feature_config.get('numeric_features', [])
categorical_features = feature_config.get('categorical_features', [])
# Create preprocessing pipeline
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), numeric_features),
('cat', OneHotEncoder(drop='first', sparse_output=False, handle_unknown='ignore'),
categorical_features)
],
remainder='passthrough' # Keep other columns as-is
)
# Select model based on configuration
if self.config['model_type'] == 'random_forest':
model = RandomForestClassifier(
n_estimators=100,
max_depth=10,
random_state=self.config['random_state'],
n_jobs=self.config['n_jobs']
)
elif self.config['model_type'] == 'logistic_regression':
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(
random_state=self.config['random_state'],
max_iter=1000,
n_jobs=self.config['n_jobs']
)
else:
raise ValueError(f"Unsupported model type: {self.config['model_type']}")
# Create complete pipeline
self.pipeline = Pipeline([
('preprocessor', preprocessor),
('classifier', model)
])
self.logger.info(f"Built pipeline with {self.config['model_type']} model")
return self.pipeline
def train(self, X, y, feature_config):
"""Train the model with comprehensive validation"""
if self.pipeline is None:
self.build_pipeline(feature_config)
self.logger.info("Starting model training...")
training_start = datetime.now()
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=self.config['test_size'],
random_state=self.config['random_state'],
stratify=y
)
# Hyperparameter tuning if enabled
if self.config['hyperparameter_tuning']:
self.pipeline = self._tune_hyperparameters(X_train, y_train)
# Train final model
self.pipeline.fit(X_train, y_train)
self.is_trained = True
# Evaluate model
train_score = self.pipeline.score(X_train, y_train)
test_score = self.pipeline.score(X_test, y_test)
# Cross-validation
cv_scores = cross_val_score(
self.pipeline, X, y,
cv=self.config['cv_folds'],
scoring='accuracy'
)
# Generate detailed evaluation
y_pred = self.pipeline.predict(X_test)
classification_rep = classification_report(y_test, y_pred, output_dict=True)
# Store training metadata
self.training_metadata = {
'training_time': (datetime.now() - training_start).total_seconds(),
'train_accuracy': train_score,
'test_accuracy': test_score,
'cv_mean': cv_scores.mean(),
'cv_std': cv_scores.std(),
'train_samples': len(X_train),
'test_samples': len(X_test),
'feature_count': X.shape[1],
'classification_report': classification_rep,
'model_config': self.config,
'timestamp': datetime.now().isoformat()
}
self.logger.info(f"Training completed. Test accuracy: {test_score:.4f}")
return self.training_metadata
def _tune_hyperparameters(self, X_train, y_train):
"""Perform hyperparameter tuning"""
self.logger.info("Starting hyperparameter tuning...")
if self.config['model_type'] == 'random_forest':
param_grid = {
'classifier__n_estimators': [50, 100, 200],
'classifier__max_depth': [5, 10, 15, None],
'classifier__min_samples_split': [2, 5, 10],
'classifier__min_samples_leaf': [1, 2, 4]
}
elif self.config['model_type'] == 'logistic_regression':
param_grid = {
'classifier__C': [0.1, 1.0, 10.0, 100.0],
'classifier__penalty': ['l1', 'l2'],
'classifier__solver': ['liblinear', 'saga']
}
grid_search = GridSearchCV(
self.pipeline,
param_grid,
cv=3, # Reduced for faster tuning
scoring='accuracy',
n_jobs=self.config['n_jobs'],
verbose=1
)
grid_search.fit(X_train, y_train)
self.logger.info(f"Best parameters: {grid_search.best_params_}")
self.logger.info(f"Best CV score: {grid_search.best_score_:.4f}")
return grid_search.best_estimator_
def predict(self, X):
"""Make predictions with the trained model"""
if not self.is_trained:
raise ValueError("Model must be trained before making predictions")
predictions = self.pipeline.predict(X)
probabilities = self.pipeline.predict_proba(X) if hasattr(self.pipeline, 'predict_proba') else None
return {
'predictions': predictions.tolist(),
'probabilities': probabilities.tolist() if probabilities is not None else None
}
def save_model(self, filepath):
"""Save the trained model with metadata"""
if not self.is_trained:
raise ValueError("Cannot save untrained model")
model_data = {
'pipeline': self.pipeline,
'metadata': self.training_metadata,
'config': self.config
}
joblib.dump(model_data, filepath)
self.logger.info(f"Model saved to {filepath}")
@classmethod
def load_model(cls, filepath):
"""Load a saved model"""
model_data = joblib.load(filepath)
instance = cls(config=model_data['config'])
instance.pipeline = model_data['pipeline']
instance.training_metadata = model_data['metadata']
instance.is_trained = True
return instance
def get_feature_importance(self):
"""Get feature importance if available"""
if not self.is_trained:
raise ValueError("Model must be trained first")
if hasattr(self.pipeline.named_steps['classifier'], 'feature_importances_'):
return self.pipeline.named_steps['classifier'].feature_importances_
else:
return None
# Example usage with comprehensive validation
def train_production_model():
"""Example of training a production-ready model"""
# Load data
data = pd.read_csv('user_behavior_dataset.csv')
# Define features
feature_config = {
'numeric_features': ['age', 'income', 'session_duration', 'page_views'],
'categorical_features': ['gender', 'device_type', 'region', 'subscription_type']
}
# Prepare data
X = data[feature_config['numeric_features'] + feature_config['categorical_features']]
y = data['target']
# Initialize and train pipeline
ml_pipeline = ProductionMLPipeline({
'model_type': 'random_forest',
'hyperparameter_tuning': True,
'cv_folds': 5
})
# Train model
results = ml_pipeline.train(X, y, feature_config)
# Save model
ml_pipeline.save_model('models/production_model.pkl')
# Print results
print(f"Model Performance:")
print(f" Test Accuracy: {results['test_accuracy']:.4f}")
print(f" CV Score: {results['cv_mean']:.4f} ± {results['cv_std']:.4f}")
print(f" Training Time: {results['training_time']:.2f} seconds")
return ml_pipeline
# Load and use trained model
def use_trained_model():
"""Example of loading and using a trained model"""
# Load model
model = ProductionMLPipeline.load_model('models/production_model.pkl')
# Make predictions on new data
new_data = pd.DataFrame({
'age': [25, 35, 45],
'income': [50000, 75000, 100000],
'session_duration': [120, 180, 90],
'page_views': [5, 8, 3],
'gender': ['M', 'F', 'M'],
'device_type': ['mobile', 'desktop', 'tablet'],
'region': ['US', 'EU', 'ASIA'],
'subscription_type': ['basic', 'premium', 'basic']
})
predictions = model.predict(new_data)
return predictions
if __name__ == "__main__":
# Train model
trained_model = train_production_model()
# Use model for predictions
predictions = use_trained_model()
print(f"Predictions: {predictions}")
Model Comparison for A/B Testing
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report, confusion_matrix
import mlflow
import mlflow.sklearn
class ModelExperiment:
def __init__(self, experiment_name):
mlflow.set_experiment(experiment_name)
self.models = {
'random_forest': RandomForestClassifier(n_estimators=100, random_state=42),
'gradient_boosting': GradientBoostingClassifier(n_estimators=100, random_state=42),
'logistic_regression': LogisticRegression(random_state=42, max_iter=1000)
}
def run_experiment(self, X_train, X_test, y_train, y_test):
"""Run experiment comparing multiple models"""
results = {}
for model_name, model in self.models.items():
with mlflow.start_run(run_name=model_name):
# Train model
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
y_prob = model.predict_proba(X_test)[:, 1] if hasattr(model, 'predict_proba') else None
# Calculate performance metrics
accuracy = model.score(X_test, y_test)
# Log to MLflow
mlflow.log_param("model_type", model_name)
mlflow.log_metric("accuracy", accuracy)
if hasattr(model, 'feature_importances_'):
# Log feature importance
feature_importance = dict(zip(
X_train.columns,
model.feature_importances_
))
mlflow.log_params(feature_importance)
# Save model
mlflow.sklearn.log_model(model, f"{model_name}_model")
results[model_name] = {
'accuracy': accuracy,
'model': model,
'predictions': y_pred
}
return results
MLOps Production Tips
1. Model Version Management:
- Manage model lifecycle with MLflow Model Registry
- Include metadata in models (training date, data version, etc.)
2. Deployment Optimization:
- Convert to ONNX format for improved inference performance
- Reduce model size with quantization
3. Monitoring:
- Detect input data distribution changes (Data Drift)
- Automated alerts for model performance degradation
Running Locally
Let’s build a complete MLOps pipeline using NumPy, Pandas, and Scikit-Learn as learned above. Theory alone is not enough—get hands-on and practice!
Create and Activate Virtual Environment
# Create virtual environment
python3 -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
# Result: (venv) prompt appears, indicating the environment is active
Install Dependencies
# Install required packages
pip3 install numpy pandas scikit-learn fastapi uvicorn
# Result: Required packages are installed and progress is shown
# Collecting numpy>=1.26.0
# Collecting pandas>=2.1.0
# Collecting scikit-learn>=1.3.2
# ...
# Successfully installed numpy-1.26.0 pandas-2.1.0 scikit-learn-1.3.2 ...
Data Preprocessing
# preprocess.py
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
import pickle
import os
def preprocess_data():
"""Generate and preprocess sample data"""
# Generate sample user behavior data
np.random.seed(42)
n_samples = 1000
data = pd.DataFrame({
'age': np.random.randint(18, 65, n_samples),
'income': np.random.normal(50000, 15000, n_samples),
'session_duration': np.random.exponential(120, n_samples),
'page_views': np.random.poisson(5, n_samples),
'purchases': np.random.binomial(1, 0.3, n_samples)
})
# Feature engineering
data['income_age_ratio'] = data['income'] / data['age']
data['engagement_score'] = (data['session_duration'] * data['page_views']) / 100
# Prepare features and target
features = ['age', 'income', 'session_duration', 'page_views', 'income_age_ratio', 'engagement_score']
X = data[features]
y = data['purchases']
# Feature scaling
scaler = StandardScaler()
X_scaled = pd.DataFrame(scaler.fit_transform(X), columns=features)
# Save processed data
os.makedirs('data', exist_ok=True)
X_scaled.to_csv('data/X.csv', index=False)
y.to_csv('data/y.csv', index=False)
# Save scaler for production use
with open('data/scaler.pkl', 'wb') as f:
pickle.dump(scaler, f)
print("✅ Data preprocessing complete")
print(f"📊 Dataset shape: {X_scaled.shape}")
print(f"🎯 Target distribution: {y.value_counts().to_dict()}")
return X_scaled, y
if __name__ == "__main__":
preprocess_data()
# Run data preprocessing
python3 preprocess.py
# Result: Data preprocessing is complete and the following files are generated
# ✅ Data preprocessing complete
# 📊 Dataset shape: (1000, 6)
# 🎯 Target distribution: {0: 700, 1: 300}
# data/X.csv # Preprocessed input data
# data/y.csv # Preprocessed target data
# data/scaler.pkl # Scaler parameters
Model Training
# train_model.py
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.metrics import accuracy_score, classification_report
import pickle
import os
def train_model():
"""Train and evaluate ML model"""
# Load processed data
X = pd.read_csv('data/X.csv')
y = pd.read_csv('data/y.csv').squeeze()
# Split data
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42, stratify=y
)
# Train model
model = RandomForestClassifier(n_estimators=100, max_depth=10, random_state=42)
model.fit(X_train, y_train)
# Evaluate model
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
cv_scores = cross_val_score(model, X_train, y_train, cv=5)
print("🎯 Model training results:")
print(f" Test accuracy: {accuracy:.4f}")
print(f" Cross-validation score: {cv_scores.mean():.4f} ± {cv_scores.std():.4f}")
print("\n📈 Classification report:")
print(classification_report(y_test, y_pred))
# Save model
os.makedirs('model', exist_ok=True)
with open('model/model.pkl', 'wb') as f:
pickle.dump(model, f)
print("💾 Model saved to model/model.pkl")
return model
if __name__ == "__main__":
train_model()
# Run model training
python3 train_model.py
# Result: Model training is complete and the following output is shown
# 🎯 Model training results:
# Test accuracy: 0.8500
# Cross-validation score: 0.8400 ± 0.0200
# 📈 Classification report:
# ...
# 💾 Model saved to model/model.pkl
Run API Server
# predict_api.py
from fastapi import FastAPI, HTTPException
import pandas as pd
import numpy as np
import pickle
from pydantic import BaseModel
import uvicorn
app = FastAPI(
title="MLOps Prediction API",
description="Production-grade ML API for hands-on MLOps practice",
version="1.0.0"
)
# Load model and scaler at startup
with open('model/model.pkl', 'rb') as f:
model = pickle.load(f)
with open('data/scaler.pkl', 'rb') as f:
scaler = pickle.load(f)
class PredictionRequest(BaseModel):
age: float
income: float
session_duration: float
page_views: int
@app.get("/")
async def root():
return {"message": "MLOps Prediction API is running!", "status": "healthy"}
@app.get("/health")
async def health_check():
return {"status": "healthy", "model_loaded": model is not None}
@app.post("/predict")
async def predict(request: PredictionRequest):
try:
# Feature engineering
income_age_ratio = request.income / request.age
engagement_score = (request.session_duration * request.page_views) / 100
# Prepare and scale features
features = np.array([[
request.age, request.income, request.session_duration,
request.page_views, income_age_ratio, engagement_score
]])
features_scaled = scaler.transform(features)
# Make prediction
prediction = model.predict(features_scaled)[0]
probability = model.predict_proba(features_scaled)[0][1]
return {
"prediction": int(prediction),
"probability": float(probability),
"confidence": "High" if probability > 0.8 else "Medium" if probability > 0.6 else "Low",
"input_features": request.dict()
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"Prediction error: {str(e)}")
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
# Run API server
python3 predict_api.py
# Result: FastAPI server starts and the following message is shown
# INFO: Started server process [xxxxx]
# INFO: Waiting for application startup.
# INFO: Application startup complete.
# INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)
API Test and Verification
Once the server is running, you can test the API as follows:
Deactivate Virtual Environment
# Deactivate virtual environment
deactivate
# Result: (venv) prompt disappears, indicating the environment is deactivated
You have successfully built a complete MLOps pipeline using NumPy, Pandas, and Scikit-Learn:
- ✅ Data preprocessing including feature engineering
- ✅ Model training with proper evaluation
- ✅ Production-grade API with comprehensive error handling
- ✅ Health check and monitoring endpoints
- ✅ Scalable architecture ready for containerization
Production Deployment: FastAPI + Docker
Let’s examine a complete example of deploying ML models in a real service environment.
1. FastAPI-based Inference Server
# app.py
from fastapi import FastAPI, HTTPException, UploadFile, File
from pydantic import BaseModel
import pandas as pd
import joblib
import numpy as np
from typing import List
import io
app = FastAPI(title="ML Model API", version="1.0.0")
# Global variable for model loading
model = None
@app.on_event("startup")
async def load_model():
"""Load model when application starts"""
global model
try:
model = joblib.load('model/production_model.pkl')
print("Model loaded successfully.")
except Exception as e:
print(f"Model loading failed: {e}")
class PredictionRequest(BaseModel):
"""Single prediction request schema"""
age: int
income: float
session_duration: float
gender: str
device_type: str
region: str
class BatchPredictionRequest(BaseModel):
"""Batch prediction request schema"""
data: List[PredictionRequest]
@app.get("/")
async def health_check():
"""Health check endpoint"""
return {"status": "healthy", "model_loaded": model is not None}
@app.post("/predict")
async def predict_single(request: PredictionRequest):
"""Single data prediction"""
if model is None:
raise HTTPException(status_code=503, detail="Model is not loaded.")
try:
# Convert input data to DataFrame
input_data = pd.DataFrame([request.dict()])
# Perform prediction
prediction = model.predict(input_data)[0]
probability = model.predict_proba(input_data)[0].tolist()
return {
"prediction": int(prediction),
"probability": probability,
"input_data": request.dict()
}
except Exception as e:
raise HTTPException(status_code=400, detail=f"Prediction failed: {str(e)}")
@app.post("/predict_batch")
async def predict_batch(request: BatchPredictionRequest):
"""Batch data prediction"""
if model is None:
raise HTTPException(status_code=503, detail="Model is not loaded.")
try:
# Convert batch data to DataFrame
input_data = pd.DataFrame([item.dict() for item in request.data])
# Perform batch prediction
predictions = model.predict(input_data).tolist()
probabilities = model.predict_proba(input_data).tolist()
return {
"predictions": predictions,
"probabilities": probabilities,
"batch_size": len(request.data)
}
except Exception as e:
raise HTTPException(status_code=400, detail=f"Batch prediction failed: {str(e)}")
@app.post("/predict_csv")
async def predict_csv(file: UploadFile = File(...)):
"""Prediction via CSV file upload"""
if model is None:
raise HTTPException(status_code=503, detail="Model is not loaded.")
if not file.filename.endswith('.csv'):
raise HTTPException(status_code=400, detail="Only CSV files can be uploaded.")
try:
# Read CSV file
contents = await file.read()
df = pd.read_csv(io.StringIO(contents.decode('utf-8')))
# Perform prediction
predictions = model.predict(df).tolist()
probabilities = model.predict_proba(df).tolist()
return {
"predictions": predictions,
"probabilities": probabilities,
"rows_processed": len(df)
}
except Exception as e:
raise HTTPException(status_code=400, detail=f"CSV prediction failed: {str(e)}")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
2. Docker Containerization
3. Kubernetes Deployment
# k8s-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ml-model-api
labels:
app: ml-model-api
spec:
replicas: 3
selector:
matchLabels:
app: ml-model-api
template:
metadata:
labels:
app: ml-model-api
spec:
containers:
- name: ml-api
image: your-registry/ml-model-api:latest
ports:
- containerPort: 8000
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
livenessProbe:
httpGet:
path: /
port: 8000
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /
port: 8000
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: ml-model-service
spec:
selector:
app: ml-model-api
ports:
- protocol: TCP
port: 80
targetPort: 8000
type: LoadBalancer
Performance Monitoring and Automation
1. Data Drift Detection
import pandas as pd
from scipy import stats
import numpy as np
from datetime import datetime
import warnings
class DataDriftMonitor:
def __init__(self, reference_data, threshold=0.05):
"""
Data drift monitoring class
Args:
reference_data: Reference training data
threshold: p-value threshold (default: 0.05)
"""
self.reference_data = reference_data
self.threshold = threshold
self.baseline_stats = self._calculate_baseline_stats()
def _calculate_baseline_stats(self):
"""Calculate baseline statistics from reference data"""
stats_dict = {}
for column in self.reference_data.columns:
if self.reference_data[column].dtype in ['int64', 'float64']:
stats_dict[column] = {
'mean': self.reference_data[column].mean(),
'std': self.reference_data[column].std(),
'distribution': self.reference_data[column].values
}
else:
stats_dict[column] = {
'value_counts': self.reference_data[column].value_counts().to_dict()
}
return stats_dict
def detect_drift(self, new_data):
"""Detect drift in new data"""
drift_results = {}
for column in new_data.columns:
if column not in self.baseline_stats:
continue
if new_data[column].dtype in ['int64', 'float64']:
# Numerical data: Kolmogorov-Smirnov test
ks_statistic, p_value = stats.ks_2samp(
self.baseline_stats[column]['distribution'],
new_data[column].values
)
drift_results[column] = {
'drift_detected': p_value < self.threshold,
'p_value': p_value,
'ks_statistic': ks_statistic,
'mean_shift': abs(new_data[column].mean() - self.baseline_stats[column]['mean'])
}
else:
# Categorical data: Chi-square test
new_counts = new_data[column].value_counts().to_dict()
baseline_counts = self.baseline_stats[column]['value_counts']
# Compare only common categories
common_categories = set(new_counts.keys()) & set(baseline_counts.keys())
if len(common_categories) > 1:
observed = [new_counts.get(cat, 0) for cat in common_categories]
expected = [baseline_counts.get(cat, 0) for cat in common_categories]
chi2_stat, p_value = stats.chisquare(observed, expected)
drift_results[column] = {
'drift_detected': p_value < self.threshold,
'p_value': p_value,
'chi2_statistic': chi2_stat
}
return drift_results
def generate_drift_report(self, drift_results):
"""Generate drift detection result report"""
drifted_features = [col for col, result in drift_results.items()
if result['drift_detected']]
report = {
'timestamp': datetime.now().isoformat(),
'total_features_checked': len(drift_results),
'drifted_features_count': len(drifted_features),
'drifted_features': drifted_features,
'drift_severity': 'HIGH' if len(drifted_features) > len(drift_results) * 0.3 else 'LOW',
'detailed_results': drift_results
}
return report
# Usage Example
monitor = DataDriftMonitor(reference_data=training_data)
new_batch = pd.read_csv('latest_production_data.csv')
drift_results = monitor.detect_drift(new_batch)
report = monitor.generate_drift_report(drift_results)
if report['drift_severity'] == 'HIGH':
print("⚠️ High level of data drift detected!")
print(f"Affected features: {report['drifted_features']}")
2. Automated Retraining Pipeline
import schedule
import time
from datetime import datetime, timedelta
import logging
class AutoMLPipeline:
def __init__(self, config):
self.config = config
self.logger = self._setup_logging()
self.drift_monitor = DataDriftMonitor(reference_data=None)
def _setup_logging(self):
"""Logging configuration"""
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('ml_pipeline.log'),
logging.StreamHandler()
]
)
return logging.getLogger(__name__)
def check_and_retrain(self):
"""Check data drift and retrain if necessary"""
self.logger.info("Starting data drift check")
try:
# 1. Collect latest production data
new_data = self._collect_production_data()
# 2. Detect drift
if hasattr(self, 'reference_data'):
drift_results = self.drift_monitor.detect_drift(new_data)
report = self.drift_monitor.generate_drift_report(drift_results)
# 3. Determine retraining necessity
if self._should_retrain(report):
self.logger.info("Retraining is needed. Starting retraining.")
self._retrain_model(new_data)
else:
self.logger.info("Model is stable. No retraining needed.")
else:
self.logger.info("No reference data available. Proceeding with initial training.")
self._train_initial_model(new_data)
except Exception as e:
self.logger.error(f"Error during pipeline execution: {e}")
def _collect_production_data(self):
"""Collect data from production environment"""
# In actual implementation, collect data from database, S3, Kafka, etc.
end_date = datetime.now()
start_date = end_date - timedelta(days=7)
# Example: Collect data from PostgreSQL
query = f"""
SELECT * FROM user_features
WHERE created_at BETWEEN '{start_date}' AND '{end_date}'
"""
return pd.read_sql(query, con=self.config['database_connection'])
def _should_retrain(self, drift_report):
"""Determine retraining necessity"""
return (
drift_report['drift_severity'] == 'HIGH' or
drift_report['drifted_features_count'] > 3
)
def _retrain_model(self, new_data):
"""Model retraining"""
try:
# 1. Data preprocessing
X, y = self._preprocess_data(new_data)
# 2. Train new model
new_pipeline = MLPipeline()
results = new_pipeline.train(X, y)
# 3. Validate model performance
if self._validate_new_model(new_pipeline, results):
# 4. Deploy model
self._deploy_model(new_pipeline)
self.logger.info("New model deployed successfully.")
else:
self.logger.warning("New model performance below standards.")
except Exception as e:
self.logger.error(f"Error during retraining: {e}")
def _validate_new_model(self, new_model, results):
"""Validate new model performance"""
# Compare with baseline performance
min_accuracy = self.config.get('min_accuracy', 0.8)
return results['test_accuracy'] >= min_accuracy
def _deploy_model(self, model):
"""Model deployment"""
# Timestamp for version management
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
model_path = f"models/model_{timestamp}.pkl"
# Save model
model.save_model(model_path)
# Update production model symbolic link
import os
if os.path.exists("models/production_model.pkl"):
os.remove("models/production_model.pkl")
os.symlink(model_path, "models/production_model.pkl")
# Trigger rolling update in Kubernetes (optional)
# kubectl patch deployment ml-model-api -p '{"spec":{"template":{"metadata":{"labels":{"date":"' + timestamp + '"}}}}}'
# Scheduling configuration
pipeline = AutoMLPipeline(config)
# Run daily at 2 AM
schedule.every().day.at("02:00").do(pipeline.check_and_retrain)
# Run every Monday at 1 AM
schedule.every().monday.at("01:00").do(pipeline.check_and_retrain)
# Run scheduler
while True:
schedule.run_pending()
time.sleep(60) # Check every minute
Key Points and Conclusion
-
Foundation Libraries
- NumPy: High-performance numerical computing foundation for all ML frameworks
- Pandas: Data manipulation and ETL backbone for feature engineering pipelines
- Scikit-Learn: Complete ML lifecycle from experimentation to production deployment -
Production Capabilities
- Real-time data processing and feature engineering at scale
- Automated model training with hyperparameter optimization
- Containerized deployment with Docker and Kubernetes
- Comprehensive monitoring and automated retraining workflows -
Best Practices
- Use vectorized operations for 10-100x performance improvements
- Implement proper data validation and quality checks
- Design pipelines for reproducibility and version control
- Monitor data drift and model performance in production
The transition from DevOps to MLOps is no longer optional—it’s essential for modern infrastructure teams. NumPy, Pandas, and Scikit-Learn aren’t just data science tools; they’re the foundational components of modern AI service infrastructure that enable data-driven applications at scale.
Core Takeaways
- NumPy: Provides the high-performance numerical foundation that makes real-time data processing feasible
- Pandas: Serves as the central hub for data pipelines and feature stores in production systems
- Scikit-Learn: Delivers complete ML workflows from experimentation to production deployment
Next Steps for Expansion
With these fundamentals mastered, consider expanding into advanced MLOps technologies:
| Technology Category | Recommended Tools and Platforms |
|---|---|
| Experiment Management | MLflow, Weights & Biases, Neptune.ai for tracking experiments and model versioning |
| Workflow Orchestration | Kubeflow, Argo Workflows, Apache Airflow for automating ML pipelines |
| Real-time Processing | Apache Kafka, Apache Spark, Apache Flink for streaming data processing |
| Model Serving | KServe, Seldon Core, TorchServe, TensorFlow Serving for production model deployment |
| Monitoring & Observability | Prometheus + Grafana, Evidently AI, WhyLabs for model and data monitoring |
MLOps represents more than an extension of DevOps—it’s a fundamental shift toward data-centric thinking that enables entirely new dimensions of service operation and intelligence. The skills you’ve learned here provide the foundation for building AI-native applications that can adapt, learn, and improve over time.
Start implementing these concepts today to prepare for the AI-driven future of software infrastructure!

Comments